Einführung in die DH
2023-10-30
Sitzung 1 (31.10.2023)
Definitionen der DH
Eleonora Arrigoni / Carina Zander
“DH is to take advantage of digital resources to improve our work as philologists.” – Eleonora Arrigoni
Gideon Burton / Bianca Ottenberg
„To me digital humanities is not adding computing to traditional humanities subjects; it is rethinking our subjects and core activities (teaching, scholarship) as the new communications media take us to new questions, new modes of creativity, and new connections among people and ideas.“ – Gideon Burton
Torsten Schaßan / Ben Conrad
DH is part of what once was called ‘auxillary sciences’ in the humanities in the best sense: To know about the theory and methods of carrying out scholarly work in a digital way and in the digital age is prerequisite to all work done. – Torsten Schaßan
Stan Ruecker / Rachel Georg
“Researchers working with digital materials, tools, or methods in the humanities; researchers creating new digital materials, tools, or methods in the humanities; researchers studying computing using humanities methods.” – Stan Ruecker
Timothy Lepczyk / Anna-Lena Volkwein
“Technology and computing are used to reexamine traditional humanities research and explore new modes of scholarship.” – Timothy Lepczyk
Katie Kaczmarek / Phillip Schmitz
“To me, digital humanities is about exploring the ways in which the affordances of technology can help us explore the deeper concerns of the humanities, from expanding archival access to thinking about what it means to read something. DH embodies a spirit of collaboration, experimentation, and play, in which failure is acceptable and part of the normal process, and in which the action of ‘making’ is as valued as the action of thinking.” – Katie Kaczmarek
Jürgen Knauth / Rebecca Daniel
“Personally, I don’t define DH. Definitions should be done by others than myself. But I have a pretty clear understanding what I think DH is: DH is the ‘place’ where various disciplines meet, especially informatics and humanities. There are numerous of problems that can only be solved if those expertises are brought together. The project I’m working on - SeNeReKo - is a great example for such co-operation of multiple disciplines.” – Jürgen Knauth
Francesca Morselli / Nune Arazyan
Convergence and Inclusion. The first because different disciplines are collaborating to create common languages. The latter as DH allow peripheral or hidden resources to be taken into consideration in the development of research questions. – Francesca Morselli
Lektüreempfehlungen
- Thaller, “DH als Wissenschaft”, 2017
- Drucker, “1a: What is Digital Humanities”, 2021
- Sugimoto and Weingart: “The Kaleidoscope of Disciplinarity”, 2015, https://www.emerald.com/insight/content/doi/10.1108/jd-06-2014-0082/full/html
Sitzung 2 (7.11.2023)
Open Access und Open Science
Neue Einsichten
- Neu war für mich, dass Open Access nicht der Überbegriff ist, sondern ein Teil von Open Science
- Unterscheidung und Definition der verschiedenen Typen von Open Access Publikationen
- Der Begriff Author bzw. Article Processing Charge und die Höhe der Gebühren
- Diversität der Typen von Geschäftsmodellen
- Aspekte zur Zugänglichkeit für Maschinen (jenseits von PDF)
- Breite der Variationen bei den Lizenzen
- Ressourcen wie DOAJ, um OA-Zeitschriften zu finden
Ressourcen zu Open Access
Fragen: Open Access allgemein
- Gibt es auch Nachteile von Open Access? Wenn ja, wie wird mit ihnen umgegangen?
- Welche zukünftigen Entwicklungen sind im Bereich Open Access zu erwarten?
- Wie hat Open Access vor dem Internet funktioniert? (War das ausschließlich in Bibliotheken möglich?)
- Welche Unterschiede gibt es in Hinblick auf Open Access zwischen verschiedenen Disziplinen?
Eingeschränkter Open Access
- Ist es möglich eine Emabrgofrist zu verlängern?
- Was bedeutet Repository bei den Green OAs?
- Was genau ist eine Zweitveröffentlichung?
Qualitätssicherung und Reputation
- Werden alle OA Publikationen vor ihrer Publikation geprüft?
- Wie funktioniert Open Peer Review?
- Warum werden Gold OA-Publikationen weniger zitiert als z.B. closed Publikationen?
- Wird OA-Publikationen weniger vertraut? Gelten sie als weniger wert oder weniger zitierbar?
Geschäftsmodelle
- Wie kann ich mir individuelles Engagement (z.B. Selbstausbeutung) als ein mögliches Geschäftsmodell konkret vorstellen?
- Wer trägt die kosten bei den Article Processing Charges und wie läuft das ab?
- Wie genau wird das Honorar von Open Access Autoren festgelegt?
- Welche Vor- und Nachteile haben die unterschiedlichen Geschäftsmodelle bzw. welche werden hauptsächlich genutzt?
- Gibt es Spannungen im Verhältnis zwischen herkömmlichen/kommerziellen und Open Access Verlagen?
Verschiedenes
- Warum Attribute wie “has_thesis” (ambig?) oder “has_conclusion” vergeben? Das lässt sich doch schwer automatisieren (wer annotiert das? die Autoren selbst?) Könnte man das nicht besser über den Inhalt der Volltexte regeln mit similarity measures/Hashtags/Schlagwörter/Abstracts?
- Was bedeuten Lizenzen wie “Apache” oder die “MIT” Lizenz? sind sie ähnlich zu Creative Commons Lizenz?
Sitzung 3 (14. Nov. 2023):
Digitalisierung
Überblick
- Ihre Fragen zum Thema Digitalisierung
- Literatur zu OCR/HTR mit traditionellen vs. Deep-Learning-basierten Ansätzen
Bit-stream-preservation
Frage: Ich würde gern etwas darüber erfahren, wie bit-stream-preservation funktioniert.
Digitale Daten sind fundamental und physisch auf dem Datenträger ein “Bitstream”, also eine Folge von Bits (0/1).
Bitstream Preservation ist die Fähigkeit, den Bitstream über Technologiewechsel (bspw. HDD zu SSD) hinaus zu erhalten.
Zuverlässige Bitstream Preservation ist fundamental für die LZA (Langzeitarchivierung), aber nicht ausreichend für Interoperabilität (passende Software + Dokumentation).
Dafür muss der Bitstream u.a. redundant (mehrfach) gespeichert werden; und er muss regelmäßig auf neue Speichermedien übertragen werden (wegen Alterung oder Technologiewechsel)
Quelle:
- Bistream-Preservation im nestor-Handbuch: https://nestor.sub.uni-goettingen.de/handbuch/artikel/nestor_handbuch_artikel_163.pdf
Quantisierung: Screencast / Rehbein 2017

Beispiel: Ausgangsbild (“Objekt”)

- Angenommen, wir machen mit einer Kamera ein Foto eines Fussballs…
Quantisierung 1: Zeit/Raum, hier: Auflösung

- Wir stellen die Kamera auf 17x17 Pixel ein ;-)
Quantisierung 2: Werte, hier: Graustufen

- Binär bis 256 Graustufen; wir wählen 16 Abstufungen.
Ergebnis: Aufnahme mit 17x17 Pixeln und 16 Graustufen

- Ergebnis: Der Ball ist gerade so zu erkennen.
Weitere OCR-Fragen
- Was ist das Prinzip der geometrischen Primitive? Grundformen (Bögen, Gerade, Winkel)
- Textfelderkennung bei OCR: eigener Classifier für Text / Tabelle / Bild
- Kostenfreien OCR-Programe neben OCR4all: Tesseract (HP/Google), OCRopus (Google)
- Digitalisierung: Scanner oder Digitalkamera? (Je nach Material)
Weitere Fragen
- Was ist das Prinzip der geometrischen Primitive?
- HSL: Werden die Farben beim HSL Farbraum gleich wie beim RGB Farbraum aufgeschrieben? Bspw.: G200xR300xB150.
- Textfelderkennung bei OCR
- Kostenfreien OCR-Programe neben OCR 4 All
- Frage: Ich würde gerne vertiefende Informationen zu OCR in Form von Visualisationen der vier Prozessschritte erhalten.
- Die Funktionsweise eines Bayer-Sensors. Wie funktioniert Interpolation?
- Würden Sie für die Digitalisierung in den DH eher Scanner und Digitalkameras empfehlen? In der Museologie werden häufig eher Kameras empfohlen (Kontaktlos, schneller…).
- Wie genau kann ich mir die Zeichenerkennung vorstellen? Für mich ist es unvorstellbar, dass künstliche Intelligenz Zeichen präzise erkennen kann. Gilt das auch für ganz schlechte, unverständliche Schrift, wie zum Beispiel bei Briefen?
- Andere Möglichkeiten der Digitalisierung und ihre Bedeutung/Nutzen für die Digital Humanities.
OCR/HTR mit Deep Learning
Vorab: Bitte zumindest das Abstract lesen!

Einige relevante Papers
- Namysl, Marcin, and Iuliu Konya. 2019. “Efficient, Lexicon-Free OCR Using Deep Learning.” arXiv. https://doi.org/10.48550/arXiv.1906.01969.
- Nanehkaran, Y. A., Defu Zhang, S. Salimi, Junde Chen, Yuan Tian, and Najla Al-Nabhan. 2021. “Analysis and Comparison of Machine Learning Classifiers and Deep Neural Networks Techniques for Recognition of Farsi Handwritten Digits.” The Journal of Supercomputing 77 (4): 3193–3222. https://doi.org/10.1007/s11227-020-03388-7.
- Wei, Tan Chiang, U. U. Sheikh, and Ab Al-Hadi Ab Rahman. 2018. “Improved Optical Character Recognition with Deep Neural Network.” In 2018 IEEE 14th International Colloquium on Signal Processing & Its Applications (CSPA), 245–49. https://doi.org/10.1109/CSPA.2018.8368720.
- Jindal, Amar, and Rajib Ghosh. 2023. “A Hybrid Deep Learning Model to Recognize Handwritten Characters in Ancient Documents in Devanagari and Maithili Scripts.” Multimedia Tools and Applications, June. https://doi.org/10.1007/s11042-023-15826-8.
Paper zu Handschriften in Devanagari und Maithili

Paper zu Handschriften in Devanagari und Maithili

Paper zu Handschriften in Devanagari und Maithili

Paper zu Handschriften in Devanagari und Maithili

Paper zu Handschriften in Devanagari und Maithili

- Accuracy: Also wohl der Anteil der Zeichen, die korrekt erkannt wurden.
Sitzung 4 (21. Nov. 2023):
Datenmodellierung 1
Datenmodellierung in DH-Projekten
Beethovens Werkstatt
- Gegenstand des Modells: musikalische Werke von Beethoven, genauer: ihre Entstehungsgeschichte (“genetische Textkritik”) auf der Grundlage der Handschriften von Beethoven
- Vereinfachung / Abstraktion: mit TEI, MEI (und Faksimiles): Normierung und Vereinfachung der Darstellung gegenüber der Handschriften; Noten, Anmerkungen, aber nicht Art der Tinte (?) oder Geruch.
- Zweck / Vorteil gegenüber Original: Analyse wird vereinfacht; Vergleich von Fassungen wird möglich; Verknüpfung von Dokumenten (Noten und Anmerkungen)
- Siehe: Demo-Edition, Seite 14, “Codierung”, lines 35 und 1795.
Dehmel Digital
- Gegenstand des Modells: Korrespondenznetz um Ida und Richard Dehmel; 35.000 Originalbriefe. Entitäten.
- Vereinfachung / Abstraktion: XML-TEI für die Textkodierung. Automatische Transkription mit HTR (viele Fehler!). Entitäten. Siehe auch Editionsrichtlinien. Kern des Datenmodells sind die Schreibenden und Adressaten, sodass sich eine Netzwerkstruktur ergibt. Datum, aber nicht Datum Verfassen vs. Absenden vs. Empfangen.
- Zweck / Vorteil gegenüber Original: Modellierung macht Netzwerk sichtbar. Netzwerkanalyse wird möglich. Volltextsuche durch Transkription. Zugriff über Netzwerk-Darstellung.
Textdatenbank und Wörterbuch des klassischen Maya
- Gegenstand des Modells: 10.000 bekannte Schriftträger zum klassischen Maya.
- Vereinfachung / Abstraktion: Derzeit: vor allem Katalogisierung von Bildaufnahmen der Schrifträger. Auch 3D-Modelle (Beispiel). Ziele aber auch: Maschinenlesbare Transkription. Zusammenführung in ein Wörterbuch.
- Zweck / Vorteil gegenüber Original: Zusammenführung von Beständen an verschiedenen Standorten. Durchsuchbarkeit wird möglich.
Story Generator Algorithms
- Gegenstand des Modells: Geschichten bzw. der Schreibprozess von Geschichten.
- Vereinfachung/Abstraktion: Vier Bereiche, die für Geschichten notwendig sind: Zieldomäne (“story-telling goals”), Wissensdomäne (Lexikon), Geschichtsdomäne (Ereignisse und Figuren), Diskursdomäne (Erzähler, Verbalizer).
- Zweck / Vorteil gegenüber Original: Vereinfachung. Generieren von Geschichten wird möglich (?). (Siehe auch Large Language Models; ganz andere Funktionsweise!)
Sitzung 5 (28. Nov. 2023):
Datenmodellierung 2 – Datenbanken
Übersicht
- Fragen zum Thema Datenbanken
- Vorteile und Nachteile von Graphdatenbanken
Normalformen
- Wozu ist die Normalisierung gut?
- Bitte genauere Informationen zur Normalisierung bzw. zu den Normalformen.
- Was ist die Boyce-Codd-Normalform? Inwieweit unterscheidet sie sich zur dritten NF und was bezweckt man mit ihrer Anwendung?
- Nochmal Hinweis auf diese Ressource: https://www.tinohempel.de/info/info/datenbank/normalisierung.htm
Edgar F. Codd
- Frage: Auf welcher Grundlage entwickelte Edgar F. Codd das relationale Datenbankmodell bzw. welches Problem wollte er damit lösen?
- Sein Kernziel war, die Datenverwaltung effizienter, flexibler und besser verständlich zu gestalten.
- Probleme
- Datenkomplexität: Hierarchische Datenbanken macht Abfragen komplex
- Datenintegrität: Es gab keinen Mechanismus, um Redundanzen zu reduzieren und konsistente Daten zu erzwingen
- Trennung von phyischem DBMS und der Interaktion mit den Daten
- Zwei “Erfindungen”:
- Relationale Datenbanken: Sammlungen von verbundenen Tabellen
- Abfragesprache SQL (Structured Query Language)
Wozu ist die Normalisierung gut?
- Sie vermeidet Redundanzen in den Daten (und dadurch auch inkonsistente Daten; leichtere Updates)
- Durch die Atomisierung werden die Daten genauer sortierbar, filterbar, durchsuchbar
- Die Daten können dadurch auch besser exportiert und weiterverarbeitet werden
- Die Tabellen werden “monothematisch” und sind dadurch besser organisiert
- Das Splitten der Tabellen hilft dabei, die Beziehungen zwischen den Tabellen explizit zu definieren
Ausgangslage: Aufenthaltsorte von Reisenden
Kompakt, alle Infos vorhanden, wenig Redundanz, aber diverse Probleme mit der Normalisierung. Verschachtelte oder gruppierte Werte (Zelleninhalte) sind vorhanden.
| name | WD-ID | places |
|---|---|---|
| Marco Polo (1254-1324) | Q6101 | Bukhara, Uzbekistan (39,64); Hormuz, Iran (27,56); Beijing, China (39,116) |
| Ibn Battuta (1304-1369) | Q7331 | Tangier, Marokko (35,5); Cairo, Ägypten (30,31); Baghdad, Irak (33,44) |
| Freya Stark (1893-1993) | Q292480 | Aleppo, Syrien, (36,37); Baghdad, Irak (33,44); Muscat, Oman (23,58) |
| Paul Theroux (1941-) | Q510320 | Cairo, Ägypten (30,31); Bogotá, Kolumbien (4,74); Phnom Penh, Kambodscha (11,104) |
Erste Normalform: Atomisierung
Jedes Attribut (Spalte) der Relation (Tabelle) hat atomare Werte. Also: Verschachtelte oder gruppierte Werte (Zelleninhalte) sind nicht vorhanden. Zweck: Sortierung, Suche. Aber: viel Redundanz.
| last | first | born | died | WD-ID | city | country | lat | long |
|---|---|---|---|---|---|---|---|---|
| Polo | Marco | 1254 | 1324 | Q6101 | Bukhara | Uzbekistan | 39 | 64 |
| Polo | Marco | 1254 | 1324 | Q6101 | Hormuz | Iran | 27 | 56 |
| Polo | Marco | 1254 | 1324 | Q6101 | Beijing | China | 39 | 116 |
| Battuta | Ibn | 1304 | 1369 | Q7331 | Tangier | Marokko | 35 | 5 |
| Battuta | Ibn | 1304 | 1369 | Q7331 | Cairo | Ägypten | 30 | 31 |
| Battuta | Ibn | 1304 | 1369 | Q7331 | Baghdad | Irak | 33 | 44 |
| Stark | Freya | 1893 | 1993 | Q292480 | Aleppo | Syrien | 36 | 37 |
| Stark | Freya | 1893 | 1993 | Q292480 | Baghdad | Irak | 33 | 44 |
| Stark | Freya | 1893 | 1993 | Q292480 | Muscat | Oman | 23 | 58 |
| Theroux | Paul | 1941 | n/a | Q510320 | Cairo | Ägypten | 30 | 31 |
| Theroux | Paul | 1941 | n/a | Q510320 | Bogotá | Kolumbian | 4 | 74 |
| Theroux | Paul | 1941 | n/a | Q510320 | Phnom Penh | Kambodscha | 11 | 104 |
Zweite Normalform: Abhängigkeit (voriger Zustand)
Jedes Nicht-Schlüssel-Attribut (nicht Teil eines Schlüssels) ist jeweils von jedem ganzen Schlüsselkandidaten abhängig, nicht nur von einem Teil eines Schlüsselkandidaten. Schlüsselkandidaten hier: “last” oder “WD-ID” + “city” = Ortsbesuch einer Person. Nur eine Kombination ist eindeutig, mache Attribute sind von einem Teil der Schlüssel abhängig. Wir müssen die Relationen (Tabellen) splitten. Reduziert zugleich die Redundanz.
| last | first | born | died | WD-ID | city | country | lat | long |
|---|---|---|---|---|---|---|---|---|
| Polo | Marco | 1254 | 1324 | Q6101 | Bukhara | Uzbekistan | 39 | 64 |
| Polo | Marco | 1254 | 1324 | Q6101 | Hormuz | Iran | 27 | 56 |
| Polo | Marco | 1254 | 1324 | Q6101 | Beijing | China | 39 | 116 |
| Battuta | Ibn | 1304 | 1369 | Q7331 | Tangier | Marokko | 35 | 5 |
| Battuta | Ibn | 1304 | 1369 | Q7331 | Cairo | Ägypten | 30 | 31 |
| Battuta | Ibn | 1304 | 1369 | Q7331 | Baghdad | Irak | 33 | 44 |
| Stark | Freya | 1893 | 1993 | Q292480 | Aleppo | Syrien | 36 | 37 |
| Stark | Freya | 1893 | 1993 | Q292480 | Baghdad | Irak | 33 | 44 |
| Stark | Freya | 1893 | 1993 | Q292480 | Muscat | Oman | 23 | 58 |
| Theroux | Paul | 1941 | n/a | Q510320 | Cairo | Ägypten | 30 | 31 |
| Theroux | Paul | 1941 | n/a | Q510320 | Bogotá | Kolumbian | 4 | 74 |
| Theroux | Paul | 1941 | n/a | Q510320 | Phnom Penh | Kambodscha | 11 | 104 |
Zweite Normalform: Abhängigkeit von Schlüssel-Attributen (a)
Jedes Nicht-Schlüssel-Attribut (nicht Teil eines Schlüssels) ist jeweils von jedem ganzen Schlüsselkandidaten abhängig, nicht nur von einem Teil eines Schlüsselkandidaten. Schlüsselkandidaten: “last” oder “WD-ID” für Personen und “city” für Städte. Das splitten reduziert die Redundanz (Personen nur noch einmal genannt).
Personen
| WD-ID | last | first | born | died |
|---|---|---|---|---|
| Q6101 | Polo | Marco | 1254 | 1324 |
| Q7331 | Battuta | Ibn | 1304 | 1369 |
| Q292480 | Stark | Freya | 1893 | 1993 |
| Q510320 | Theroux | Paul | 1941 | n/a |
Ortsbesuche
| WD-ID | city | country | lat | long |
|---|---|---|---|---|
| Q6101 | Bukhara | Uzbekistan | 39 | 64 |
| Q6101 | Hormuz | Iran | 27 | 56 |
| Q6101 | Beijing | China | 39 | 116 |
| Q7331 | Tangier | Marokko | 35 | 5 |
| Q7331 | Cairo | Ägypten | 30 | 31 |
| Q7331 | Baghdad | Irak | 33 | 44 |
| Q292480 | Aleppo | Syrien | 36 | 37 |
| Q292480 | Baghdad | Irak | 33 | 44 |
| Q292480 | Muscat | Oman | 23 | 58 |
| Q510320 | Cairo | Ägypten | 30 | 31 |
| Q510320 | Bogotá | Kolumbian | 4 | 74 |
| Q510320 | Phnom Penh | Kambodscha | 11 | 104 |
Zweite Normalform: Abhängigkeit von Schlüssel-Attributen (b)
Das war nur die eine Hälfte der Arbeit. Auch die Orte müssen normalisiert werden. Wir verwenden jetzt auch einen Identifier für “city”, weil es u.U. mehrere gleichnamige Städte geben könnte. Jede Tabelle hat jetzt eigene Identifier. Hier mit Assoziationstabelle (mit kombiniertem Schlüsse, ist aber nicht notwendig).
Personen
| WD-ID | last | first | born | died |
|---|---|---|---|---|
| Q6101 | Polo | Marco | 1254 | 1324 |
| Q7331 | Battuta | Ibn | 1304 | 1369 |
| Q292480 | Stark | Freya | 1893 | 1993 |
| Q510320 | Theroux | Paul | 1941 | n/a |
Orte
| C-ID | city | country | lat | long |
|---|---|---|---|---|
| 01 | Bukhara | Uzbekistan | 39 | 64 |
| 02 | Hormuz | Iran | 27 | 56 |
| 03 | Beijing | China | 39 | 116 |
| 04 | Tangier | Marokko | 35 | 5 |
| 05 | Cairo | Ägypten | 30 | 31 |
| 06 | Baghdad | Irak | 33 | 44 |
| 07 | Aleppo | Syrien | 36 | 37 |
| 08 | Muscat | Oman | 23 | 58 |
| 09 | Bogotá | Kolumbian | 4 | 74 |
| 10 | Phnom Penh | Kambodscha | 11 | 104 |
Ortsbesuche
| Besuchs-ID | WD-ID | C-ID |
|---|---|---|
| Q6101_01 | Q6101 | 01 |
| Q6101_02 | Q6101 | 02 |
| Q6101_03 | Q6101 | 03 |
| Q7331_04 | Q7331 | 04 |
| Q7331_05 | Q7331 | 05 |
| Q7331_06 | Q7331 | 06 |
| Q292480_07 | Q292480 | 07 |
| Q292480_06 | Q292480 | 06 |
| Q292480_08 | Q292480 | 08 |
| Q510320_05 | Q510320 | 05 |
| Q510320_09 | Q510320 | 09 |
| Q510320_10 | Q510320 | 10 |
Zweite Normalform: Abhängigkeit von Schlüssel-Attributen (c)
Das war nur die eine Hälfte der Arbeit. Auch die Orte müssen normalisiert werden. Wir verwenden jetzt auch einen Identifier für “city”, weil es u.U. mehrere gleichnamige Städte geben könnte. Hier jetzt mit Fremdschlüssel.
Personen
| WD-ID | last | first | born | died |
|---|---|---|---|---|
| Q6101 | Polo | Marco | 1254 | 1324 |
| Q7331 | Battuta | Ibn | 1304 | 1369 |
| Q292480 | Stark | Freya | 1893 | 1993 |
| Q510320 | Theroux | Paul | 1941 | n/a |
Ortsbesuche
| WD-ID | C-ID | city | country | lat | long |
|---|---|---|---|---|---|
| Q6101 | 01 | Bukhara | Uzbekistan | 39 | 64 |
| Q6101 | 02 | Hormuz | Iran | 27 | 56 |
| Q6101 | 03 | Beijing | China | 39 | 116 |
| Q7331 | 04 | Tangier | Marokko | 35 | 5 |
| Q7331 | 05 | Cairo | Ägypten | 30 | 31 |
| Q7331 | 06 | Baghdad | Irak | 33 | 44 |
| Q292480 | 07 | Aleppo | Syrien | 36 | 37 |
| Q292480 | 08 | Muscat | Oman | 23 | 58 |
| Q292480 | 06 | Baghdad | Irak | 33 | 44 |
| Q510320 | 05 | Cairo | Ägypten | 30 | 31 |
| Q510320 | 09 | Bogotá | Kolumbian | 4 | 74 |
| Q510320 | 10 | Phnom Penh | Kambodscha | 11 | 104 |
Dritte Normalform: Abhängigkeit unter den Nichtschlüssel-Attributen
Definition: es bestehen keine funktionalen Abhängigkeiten der Nichtschlüssel-Attribute untereinander. Alle Nichtschlüssel-Attribute (Spalten) sind direkt vom Schlüssel abhängig. In unserem Beispiel bereits gegeben.
Wenn es eine Postleitzahl gäbe, wäre der Ortsname jeweils davon indirekt abhängig, während die Postleitzahl direkt vom der Orts-ID abhängig wäre. Das wäre nicht ok. Man könnte eventuell argumentieren, dass der Ortsname von den Geokoordinaten abhängt; dann wäre der Ortsname auszulagern.
Aber: Man könnte hier jetzt das Besuchsjahr wunderbar eintragen, was in der Personentabelle und der Ortstabelle nicht gut zu platzieren ist, weil es ja nicht allein vom Ort oder der Person abhängig ist.
Ortsbesuche mit Jahr
| WD-ID | C-ID | year |
|---|---|---|
| Q6101 | 01 | 1288 |
| Q6101 | 02 | 1294 |
| Q6101 | 03 | 1302 |
| Q7331 | 04 | 1355 |
| Q7331 | 05 | 1350 |
| Q7331 | 06 | 1350 |
| Q292480 | 07 | 1924 |
| Q292480 | 06 | 1924 |
| Q292480 | 08 | 1912 |
| Q510320 | 05 | 1978 |
| Q510320 | 09 | 1956 |
| Q510320 | 10 | 1966 |
Fremdschlüssel versus Assoziationstabellen
- Frage: Ich würde gern genauer über Fremdschlüssel versus Assoziationstabellen sprechen - ist eine Lösung der anderen prinzipiell vorzuziehen?
- Fremdschlüssel
- Vorteil: Einfache Möglichkeit um Beziehungen auszudrücken
- Vorteil: Abfragen mit JOIN auf Fremdschlüssel-Tabellen sind effizienter
- Nachteil: Weniger flexibel und komplexer, wenn diverse n:m-Beziehungen festgehalten werden sollen
- Assoziationstabelle
- Vorteile: Sehr flexibel, vor allem bei n:m-Beziehungen
- Vorteil: Änderungen bei den Beziehungen sind einfacher
- Vorteil: die anderen Tabellen sind weniger redundant (siehe Reisen)
- Nachteil: die Abfragen können komplexer werden
Diskussion: Graphdatenbanken vs. relationale Datenbanken
Vorteile von Graphdatenbanken
- Graphdatenbanken unterstützen strukturierte, halb- und unstrukturierte Daten, während relationale Datenbanken ein festes Schema benötigen
- Die Graph-Struktur ist für die Modellierung mancher Objekte besser geeignet; Graphdatenbanken eignen sich für die Darstellung stark vernetzter Daten. Man kann Beziehungen zwischen Entitäten besser modellieren.
- Querys sind durch die Struktur manchmal vereinfacht
- Graphdatenbanken bilden Beziehungen anders ab, was auch das Ändern von Daten vereinfacht, ohne die Struktur der Datenbank nachhaltig zu verändern.
- Graphdatenbanken sind besonders von Vorteil, wenn es um komplexe Netzwerkstrukturen geht.
- Bei relationalen Datenbanken ist die Datenabfrage auch komplexer als bei Graphdatenbanken. (naja)
- Graphdatenbanken können problemlos große Datenmengen aus vielen verschiedenen Quellen verarbeiten und helfen zu verstehen, wie die Daten miteinander verbunden sind.
- Graphdatenbanken sind auch schneller als relationale Datenbanken, wenn es um die Abfrage verknüpfter Daten geht. (ggfs.)
- Man kann durch den Graph traversieren, also auch eventuell Nähe zwischen verschiedenen Entitäten berechnen. (Ja, und netzweranalytische Maße anwenden)
- Graphdatenbanken lassen sich gut erweitern, Änderungen (auch an der Struktur) kann man gut in das Netzwerk einpflegen.
- GDB bieten eine semantische Ordnung, die sich einfacher nachvollziehen lässt.
Nachteile von Graphdatenbanken / Vorteile von RDB
- Graphdatenbanken haben keine einheitliche Abfragesprache, sondern unterstützen Sprachen, wie SPARQL, GraphQL und Cypher. Die Abfragesprache SQL ist hierfür nicht verfügbar.
- Nachteil: Keine standardisierte Infrastruktur wie bei RDB (ja)
- Relationale Datenbanken sind klarer strukturiert über die tabellarische Form.
- Die SQL-Abfragen können leichter verständlich sein (SQL oder SPARQL, beides muss man lernen).
- RDB sind sehr weit verbreitet (ja)
- RDB sind nach den ACID-Eigenschaften aufgebaut: atomar, konsistent, isoliert und dauerhaft. (Ja, wobei das eher die Arbeitsweise von DBMS beschreibt)
Sitzung 6 (5. Dez. 2023):
Digitale Edition
Überblick
- Fragen zur Digitalen Edition
- Editionen und Editionstypen
“Wo fängt digitale Edition an?”
- Wo fängt digital an?
- digitalisiert vs. digital (Patrick Sahle)
- “a retrodigitised printed edition is not a scholarly digital edition”
- Wo fängt Edition an?
- Wiedergabe vs. Erschließung
- Faksimile mit/ohne Metadaten oder Kommentare vs. historisch-kritische Edition
- Wo hört Edition auf?
- Umfang und Erschließungstiefe
- Edition vs. Korpora / Textsammlung
Langzeitarchivierung von Digitalen Editionen
- Welche Bausteine müssen archiviert werden und wie können sie archiviert werden?
- Rohdaten (XML-TEI): kann gut in Daten-Repositories wie Zenodo archiviert werden
- Datenmodell (Schema-Datei): kann auch gut archiviert werden
- Editionsmodell (XSLT, CSS, Datenbankstruktur, etc.): kann man archivieren, aber nicht leicht interpretieren
- Nutzungsoberfläche / Interface: Sehr schwierig, ein Stück weit über Internet Archive
- Komplette Edition: in einem Docker-Container mit OS, Datenbank, Browser, alle Daten
Wie würde man ein PC-Spiel edieren (und archivieren?)
- PC-Spiele (ähnlich aber auch: jegliche Software mit grafischer Benutzungsoberfläche)
- Insgesamt sehr schwierig (und weit weg von historisch-kritischer Edition)
- Mehrere Optionen
- Archivierung der physischen Datenträger (Hefte, Datenträger), bspw.: Rescuing Diskmags-Projekt
- Archivierung und Publikation der Inhalte der Datenträger: https://archive.org/details/classicpcgames – teils mit, teils ohne Angabe oder Mitlieferung des Environments, bspw. Windows3.1-Emulation
- Emulation im Browser: https://archive.org/details/internetarcade
Sind digitale Editionen typischerweise Open Access?
- Kurze Antwort: Ja!
- Es gibt aber einige wenige Ausnahmen
- Beispiel: Samuel Beckett Digital Manuscript Project, https://www.beckettarchive.org/
- Gründe:
- entweder urheberrechtlich gelagert (moderne Autor:innen)
- oderrestriktive Praktiken der Nachlassverwaltenden (Kontrolle, Geschäftsmodell)
(2) Editionen und Editionstypen (nach Ihren Antworten!)
- *Faust Edition: Knowledge Site (?)
- Peter Handke Notizbücher: Knowledge Site
- Darwin Online: Online Variorum of Darwin’s Origin of Species: Knowledge Site (?)
- Thomas Gray Archive: Knowledge Site (ok)
- La dama boba: edición crítica y archivo digital: Knowledge Site
- Carl-Maria-von-Weber Gesamtausgabe: Knowledge Site
- Einstein Archives Online: Knowledge Site / Archiv (ok)
- Key Documents of German-Jewish History: Knowledge Site / Archiv (ok)
- *Samuel Beckett Digital Manuscript Project: Textarchiv (?)
- Euripides Scholia: Textarchiv
- The Book of Ben Sira: Textarchiv
- Nietzsche Source: Textarchiv
- La Entretenida: Faksimile-Ausgabe
- *Letters of 1916 / https://letters1916.ie/: Faksimile-Ausgabe (?)
- Bérardier de Bataut, Essai sur le récit: Faksimile-Ausgabe (?)
- Ödön von Horváth: Historisch-Kritische Edition: “Gesamtausgabe” (?)
- Armer Heinrich Digital: historisch-kritische Edition
- The Online Critical Pseudepigrapha: kritische Edition
- *Musil online: Historisch-kritische Ausgabe (ok)
- Fontanes Notizbücher: Kommentierte Hybrid-Edition
- Poems of Dafydd ap Gwilym: Manuskript Edition
- Bernoulli-Briefwechsel: Briefwechsel / Textarchiv
- The Casebook Project: Digital Archive: ?
Sitzung 7 (12. Dez. 2023):
Informationsvisualisierung
Überblick
- Beispiele für gelungene / weniger gelungene Visualisierungen
- Nächste Woche: vor Ort oder online?
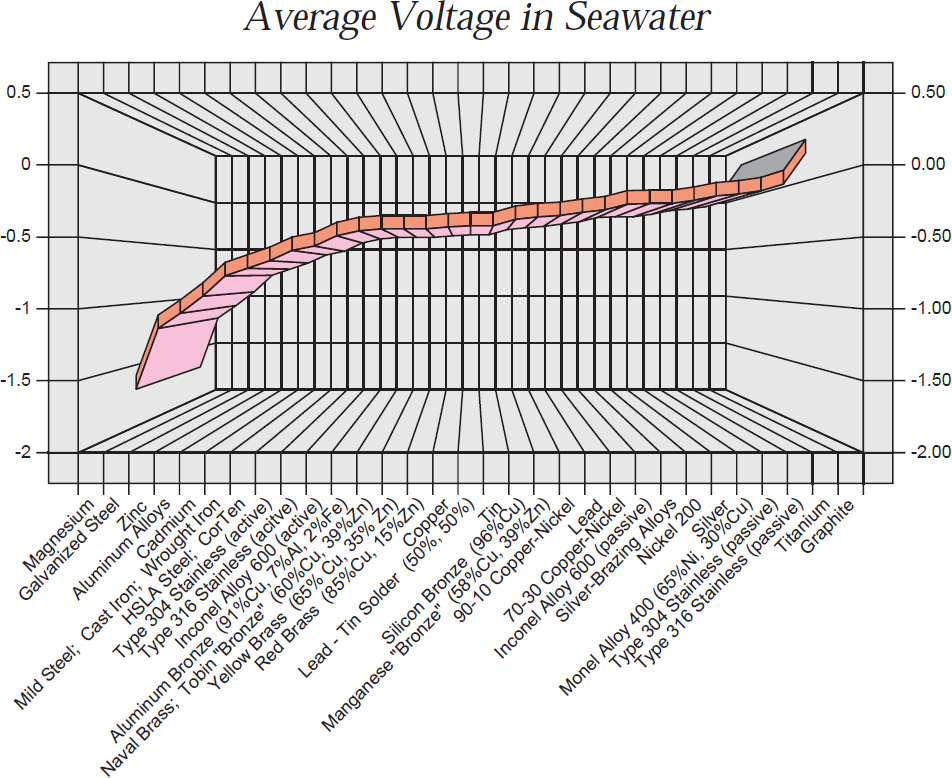
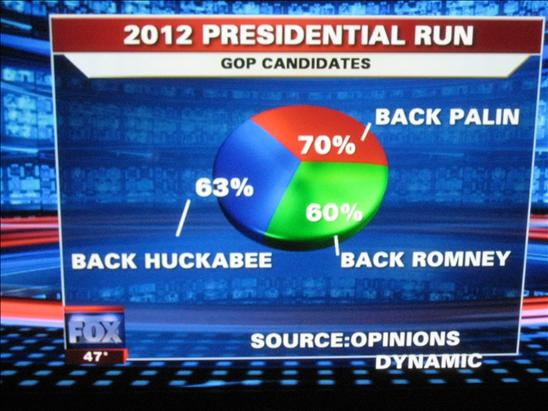
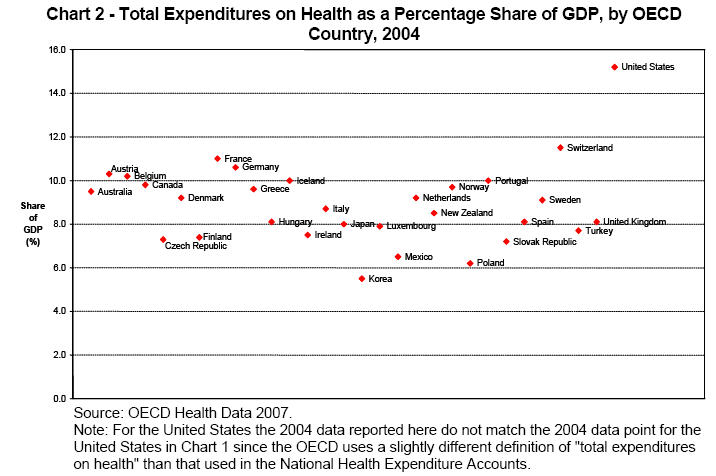
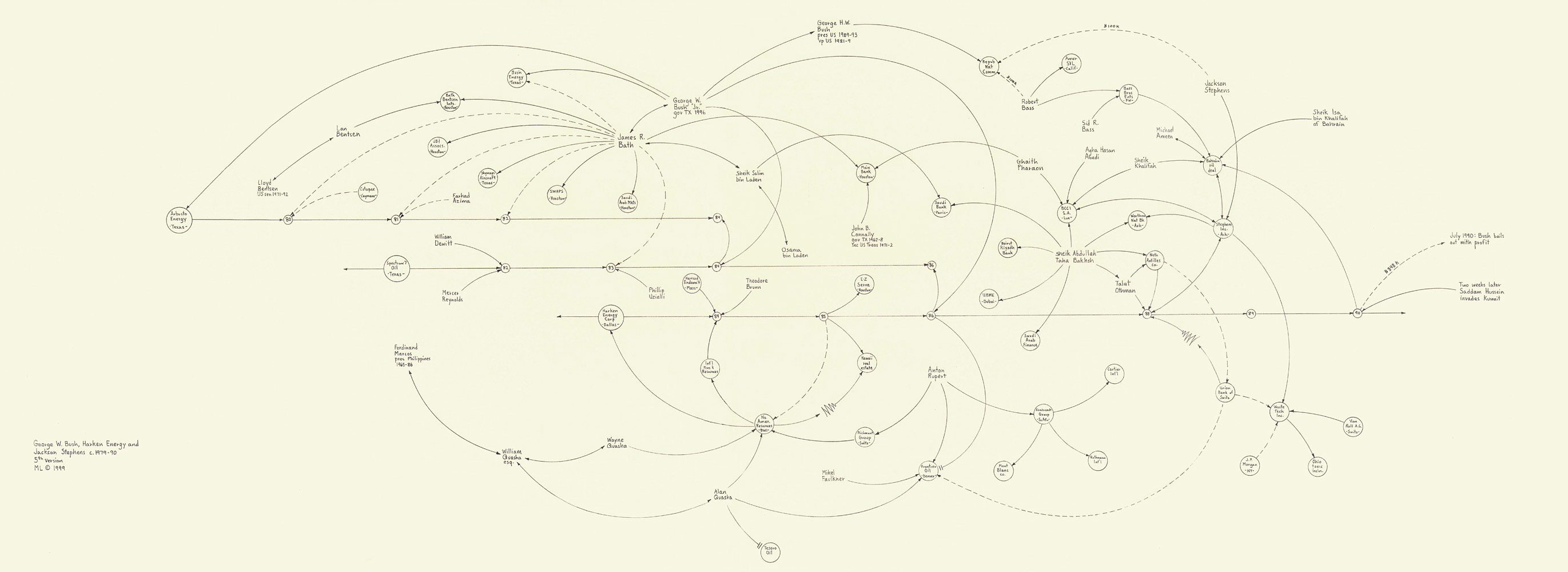
Weniger gelungene Visualisierungen
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
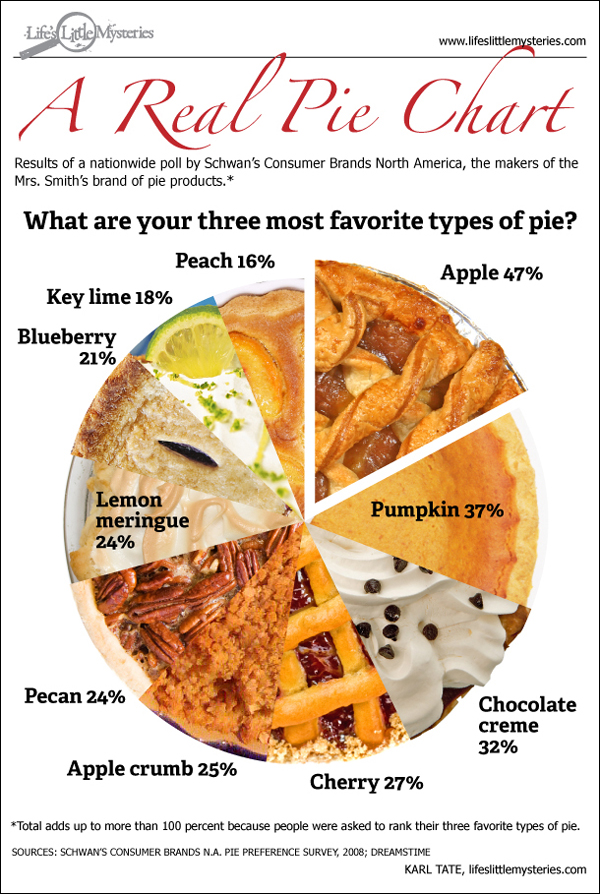{kind=link}
Sehr gelungene Visualisierungen
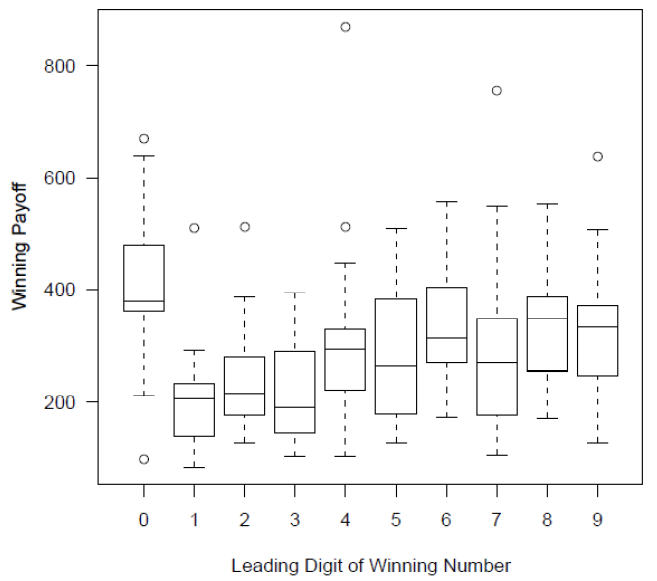{kind=link}
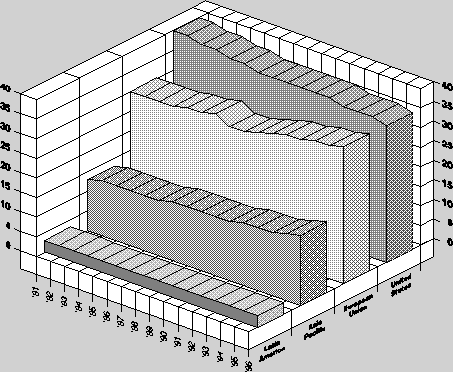{kind=link}
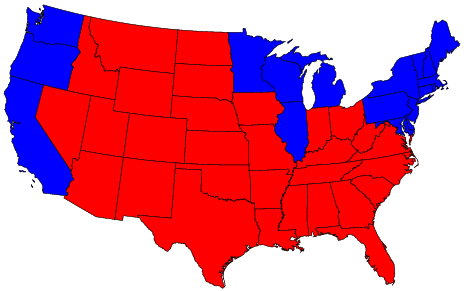{kind=link}
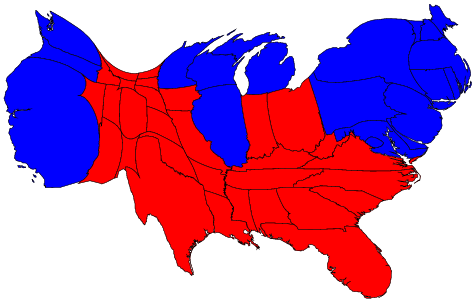{kind=link}
{kind=link}
{kind=link}
Schlussfolgerungen
- Nicht mehr Dimensionen als nötig (Health, GOP, 3D)
- Drei Dimensionen? Dann ggfs. 2 Achsen + Farbe / Größe
- Wesentliche Information soll deutlich werden (Citation)
- Datengrundlage offenlegen
- …
Ein paar Tipps zu schriftlichen Arbeiten
- Grundsätzliches
- Zentrale Frage: Welche Visualisierungsform passt am Besten zu meinen Daten?
- Welche Visualisierungsform bringt meine “key message” am besten zum Ausdruck?
- Lieber weniger Info pro Visualisierung, und mehr separate Visualisierungen, als zu viel in einer Visualisierung
- Ggfs. Link zu interaktiver Visualisierung anbieten (PyLDAViz, Bokeh, pygal)
- Praktisches
- Visualisierungen ausreichend groß darstellen
- Insbesondere: gut lesbare Beschriftung
- Manchmal ist auch eine Tabelle die bessere Wahl
Sitzung 7 (19. Dez. 2023):
Ethik in “Informatik und Digital Humanities”
Überblick
- Diskussionsfragen Ethik
- Erfahrungen mit ChatGPT
- Aktuelles zum Thema
- EU: Einigung zum AI Act
- DH: Hinweis auf ADHO Code of Conduct
- Gebru-Fall: “Stochastic-Parrots”-Paper (829 mal zitiert) – Gründung von des Distributed Artificial Intelligence Research Institute (DAIR) – Time 100 most influential people in 2022
Autorschaftsattribution
- Ist es ethisch vertretbar, Autor*innen von Werken wie in dem Beispiel zu J.K. Rowling zu identifizieren? Welche Grenzen der Privatsphäre muss Wissenschaft beachten? Kann es ein „zu viel“ geben, bei dem Menschen(gruppen) auf Daten reduziert werden?
- Weiteres Beispiel: Fall Dänemark
- Argumente pro und contra
- …
Urheberrecht und LLMs
- Sollten urheberrechtlich geschützte Daten weiterhin für das Trainieren von LLMs verwendet werden? Und: Wem sollten die Urheberrechte eines von einer KI geschriebenen Textes gehören? Darf man mit AI generierter Kunst Geld verdienen?
- Argumente pro und contra
- …
Korpusaufbau und Gender
- Wieso nur 10% Frauenquote bei den Romanen im Korpus-Projekt? Warum ist man da nicht “mutiger”? Und was ist mit Autor*innen, die nicht weiblich/männlich sind? Kann man hierbei überhaupt schon von Diversität sprechen, wenn Intersektionalität nicht berücksichtigt wurde?
- Background-Infos
- Siehe ‘diversity paradox’, “Creating ELTeC”-Paper
- Siehe ELTeC-rom
- Argumente pro und contra
- …
Der Fall der Konferenz in China
- War die Situation bei der Konferenz in China nicht vielleicht komplexer und weniger einseitig als im Screencast vorgestellt?
- Argumente
- …
ChatGPT: Vorteile und Probleme
- Anwendungsgebiete?
- Hausarbeit schreiben? Eher nicht
- Hypothese zu einem Werk generieren: auch nicht, kennt vieles nicht
- Hilfe beim Programmieren: gut, spezifisch
Inwiefern ist es hilfreich?
Welche problematischen Aspekte gibt es (praktisch oder ethisch)?
Sitzung 8 (9. Jan. 2023):
Stilometrie
Überblick
- Zu welchen Aspekten oder Punkten möchten Sie gerne ein Beispiel oder weiterführende Informationen hören?
- Suchen Sie in den Proceedings der Konferenz “Computational Humanities Research 2023” nach einem Paper, das Sie inhaltlich interessiert: Welcher Machine Learning-Ansatz wurde dort verwendet und würden Sie diesen als supervised oder unsupervised beschreiben? Link: https://ceur-ws.org/Vol-3558/
Allgemeines: Software
- Können Sie nochmal mehr auf die Software eingehen? Gibt es welche, die Sie in dem Screencast nicht vorgestellt haben?
- Es gibt sehr sehr viel Software!
- Es gibt sogar viele Tool-Inventories, bspw.: TAPOR3
- Grundfragen:
- Abwägung der Vorteile/Nachteile von alternativen Tools
- Gibt es ein (wirklich) geeignetes Tool?
- Brauche ich eine GUI oder nicht?
- Oder muss ich meinen eigenen Workflow programmieren?
Clustering oder Klassifikation
- Wie entscheidet man, ob für ein Projekt überwachtes oder unüberwachtes Machine Learning / Clustering oder Klassifikation sinnvoller ist?
- Das ergibt sich oft aus Daten und Fragestellung
- Clustering leistet ähnlichkeits-basierte Bildung von Gruppen, aber keine (explizite / klare) Kategorisierung; eher explorativ
- Klassifikation leistet Merkmals-basierte Zuordnung von Einheiten zu Kategorien, erfordert aber auch entsprechende Trainingsdaten; erlaubt Prüfen von Hypothesen
- Oft verbindet man in einem konkreten Projekt auch beide Perspektiven; Hypothesenbildung durch Clustering, Prüfung durch Klassifikation
Topic Modeling
- Genauere Informationen und ein Beispiel zum Topic Modeling
- Siehe Tutorial “Topic Modeling”
- Interaktives Topic Model Signs-at-40
Principal Components Analysis
- Im Screencast wurde auch PCA im Zusammenhang mit “dimensionality reduction” genannt; Beispiel dazu?
- Binongo: “Who Wrote the Wizard of Oz?” PDF - (Authorship Attribution)


Fokus Stilometrie
- Relative Häufigkeiten und Standardisierung: Können Sie nochmal auf den Schritt “Berechnung relativer Häufigkeiten” zu “Standardisierung” eingehen? Was sind z-scores?
- Distanz-Maße: Nutzen verschiedener Distanz-Maße: Vorteile, Nachteile, unterschiedliche Anwendungen?
- Merkmals-Matrix / Term-Dokument-Matrix: Entspricht die Merkmals-Matrix der Wortverteilung im Text nach dem Zipfschen Gesetz?
- Linkage Matrix: Was ist die Linkage-Matrix?
- => Nochmal gemeinsam auf die Folien zum Screencast schauen
CHR Papers
Wer möchte eines der Papers vorstellen? Worum geht es? Wird Clustering oder Klassifikation eingesetzt? Sonstige interessante Aspekte?
German Question Tags: A Computational Analysis - Yulia Clausen - PDF
“How Exactly does Literary Content Depend on Genre? A Case Study of Animals in Children’s Literature” - Kirill Maslinsky - PDF
Profiling Anonymous Authors in the Corsican Autonomist Press of the Interwar Period - Vincent Sarbach-Pulicani - PDF
“Comparing ChatGPT to Human Raters and Sentiment Analysis Tools for German Children’s Literature” - PDF
Is Cinema Becoming Less and Less Innovative With Time? Using neural network text embedding model to measure cultural innovation - Edgar Dubourg, Andrei Mogoutov and Nicolas Baumard - PDF
(De)constructing Binarism in Journalism: Automatic Antonym Detection in Dutch Newspaper Articles - Alie Lassche, Ruben Ros, Joris Veerbeek - PDF
Blind Dates: Examining the Expression of Temporality in Historical Photographs - Alexandra Barancová et al. - PDF
Using Online Catalogs to Estimate Economic Development in Classical Antiquity - Charles de Dampierre, Valentin Thouzeau and Nicolas Baumard - PDF
If the Sources Could Talk: Evaluating Large Language Models for Research Assistance in History - Giselle Gonzalez Garcia, Christian Weilbach - PDF
Detecting Psychological Disorders with Stylometry: the Case of ADHD in Adolescent Autobiographical Narratives - Juan Barrios, Simon Gabay, Florian Caffiero, Martin Debbané - PDF
The Middle Dutch Manuscripts Surviving from the Carthusian Monastery of Herne (14th century): Constructing an Open Dataset of Digital Transcriptions - Wouter Haverals, Mike Kestemont - PDF
Sitzung 10 (16. Jan. 2024):
Klassifikation
Überblick
- Bearbeiten Sie bitte auf der Grundlage von Screencast und Referenzlektüre die folgende Fragen: Überlegen Sie sich eine Domäne oder eine Fragestellung, für die Ihrer Meinung nach eine Klassifikationsaufgabe interessant und machbar wäre. Was für einen Datensatz bräuchte man? Und mit welchen Merkmalen könnten man ggfs. welche Kategorie ermitteln?
Antworten zur Vorstellung und Diskussion
- Genres von Texten – Beispiel Ted Underwood, HathiTrust
- Zuordnung von Gemälden zu einer Epoche bzw. Stilrichtung – Arnold / Tilton, Historical Photographs
- Automatisiertes POS-Tagging Chiche and Yitagesu, Survey
- Einteilung von Filmen oder Serien nach Genre Mangolin, Mulimodal Approach
- Analyse musealer Sammlungen – Beispiel Bobasheca et al., Cultural Metadata Quality
- Identifizierung von Social Media Bot Accounts
- Erkennen eines Betrugsfalls bei Online-Käufen
- Von welchen Lebensumständen hängt die Länge der Studienzeit ab?
Sitzung 11 (23. Jan. 2024):
NLP
Überblick
- Zu welchem NLP-Verfahren würden Sie gerne noch weitere Informationen oder ein Beispiel hören?
- Welches NLP-Verfahren halten Sie für die DH für besonders relevant, und aus welchen Gründen?
Nachfragen
Datensatz
- Frage: Wie erfahre ich am besten, welche Kriterien eine balancierte Sammlung in meinem Forschungsfall erfüllen soll?
- Antwort
- Welche Merkmale könnten theoretisch Einfluss auf die Zielgröße haben?
- Welche Merkmale sollten eigentich keinen Einfluss haben?
- Beide möchte man systematische variieren und kombinieren können, um das zu prüfen.
Beispiel Datensatz: gender / subgenre

Beispiel Datensatz: translation / subgenre

POS-Tagging / Token-basierte Annotation
- Frage: Wie ermittle ich Wahrscheinlichkeiten für nicht eindeutige Fälle beim POS-Tagging?
- Antwort:
- Das ist stark vom jeweiligen Tagger abhängig
- Redewiedergabe-Projekt: es gibt eine Option, um die Wahrscheinlichkeit mit Auszugeben
- spaCy: Hat (derzeit offenbar) nur eine Scorer zur Evaluation insgesamt, aber nicht pro Token
- NLTK: Es gibt einen cutoff-Wert (unter Wert X: keine Annotation)
- stanza: Derzeit offenbar nicht möglich
Sentiment Analyse in den DH
- Frage: Mich würde mehr Information / ein Beispiel dazu interessieren, wie Sentiment Analysis in den DH genutzt wird.
- Methoden
- Lexikon-basiert
- ML-basiert
- Beispiel
- Grisot / Herrmann: Poster
- Frage nach dem Zusammenhang von Raum und Valenz
- Annotation von Raum-Entitäten einerseits, von Sentiment der Sätze andererseits
- Prüfen, ob es einen Zusammenhang gibt
Contextualized Word Embeddings
- Frage: Ich würde gerne mehr Informationen zu Contextualized Word Embeddings hören
- Antwort:
- Grundsätzlich zwei Typen von Embeddings: statisch und contextualized
- Statisch: Ein Vektor pro Type (ohne Kontext)
- Contextualized: Ein Vektor pro Token (je nach Kontext)
- Beispiel für contextualized Embeddings: BERT
Annotation selbst trainieren
- Frage: Wie würde man einen Tagger für eine bestimmte Annotation selbst trainieren?
- Antwort am Beispiel von spacy für Objekt-Tagging
- Texte mit spaCy NER-Tagger annotieren
- Output: token-basiertes Format mit NER-Annotation
- Händisch Objekte annotieren: B-OBJ, I-OBJ, O
- NER im Trainings-Modus auf den annotierten Daten “lernen lassen”
- Auf Texten, für die eine Annotation vorliegt (die aber nicht im Trainings-Datensatz waren): => Evaluation + Fehleranalyse
- Wenn es ausreichend gut funktioniert: Auf Texten, die ganz neu und unannotiert sind
Weitere Fragen
- Ein Beispiel bzw. eine Erläuterung wie topic modeling / Latent Dirichlet Allocation (LDA) funktioniert
- Gängige NLP-Verfahren und mehrsprachige Daten
- Wie wird mit Herausforderungen wie Mehrdeutigkeit umgegangen?
- Syntactic Parsing (Wie werden Syntact Parsing Algorithmen genau implementiert und wo werden sie besonders oft angewandt?)
- Können Sie mehr über NER mit “Coreference Resolution” sagen? Wie wird die Maschine dafür trainiert?
- Basierend auf der Einordnung von Jurafsky, würden Sie Text Summarization nach aktueller Forschungslage immer noch als “still really hard” einordnen oder sogar schon als “mostly solved”?
NLP-Verfahren mit Relevanz für die DH
- Prüffragen: Welche Argumente sprechen jeweils dafür?
- Wie relevant ist das Verfahren für die DH?
- Welche Anwendungsszenarien kann man sich vorstellen?
- Wie gut / nützlich ist die Performance?
- Kandidaten
- Lemmatisierung
- Named Entity Recognition (+ Coreference Resolution)
- Sentiment Analyse
- Topic Modeling
- Machine Translation
Sitzung 12 (30. Jan. 2024):
Greening DH
Aufgabenstellung
Bitte lesen Sie die beiden folgenden Beiträge:
- Anne Baillot et al.: „Digital Humanities and the Climate Crisis. A Manifesto“, Foregrounding the Climate Crisis Within Digital Humanities Work, ohne Datum, https://dhc-barnard.github.io/dhclimate/
- Anne Baillot et al.: „Minimal Computing”, The Digital Humanities Climate Coalition Toolkit, Digital Humanities Climate Coalition, 18.11.2022, https://sas-dhrh.github.io/dhcc-toolkit/toolkit/minimal-computing.html
Und bitte beantworten Sie die folgenden Fragen:
- Gibt es einen oder mehrere Aspekte, die Sie anders sehen als die Autor:innen?
- Was war für Sie eine interessante neue Einsicht bei der Lektüre?
Neue Einsichten / große Fragen: Greening DH
- Große Verantwortung: “This would require taking a step back from detailing the environmental impact of a resource, to ask whether the activities supported by that resource really serve ecological and social justice.” (=> CLS?)
- Was bedeutet das konkret? “Advocate for mitigations (e.g. energy-efficient programming practices)” (=> minimal computing)
- Große Frage: Wie können die Rahmenbedinungen aussehen, die dazu führen, dass Forschende nicht mehr so viel Reisen müssen, um den Impact ihrer Forschung zu sichern? (=> Social Media; virtuelle Meetings; alternative Formen von Impact?)
- Super Idee: “This might very well mean organizing fewer events, but events that last longer.” (=> DH2024, CLS INFRA)
Neue Einsichten / große Fragen: Minimal Computing
- OMG! Python ist im Vergleich extrem ineffizient bei der Ausführung
- LLMs: Wegen dem Trend zur Nutzung von LLMs kaufen wir gerade diverse Server und leistungsfähige Rechner. Das ist ein Problem!
- “Minifying”: Wow, das macht einen Unterschied?
- Ja, aber wie? “Rather, lasting positive changes come when there are structures that support and encourage them.”
Was machen die DH schon?
- Hybride Optionen bei Konferenzen: DH2023 und DH2024 (recht weitgehend), DHd2023 (teilweise), DHd2024 (eingeschränkt)
- Green Web Hosting: bei dig-hum.de und adho.org kein Faktor, bei fedihum.org schon
- Seit 2016 ist das ein Thema, aber es bleibt vergleichsweise randständig
- Aktuell: Gründung einer Beratungsfirma: Stripes and Strings – Sustainable Digital Humanities for Research and Heritage
Abweichende Positionen?
- Eigentlich finde ich das alles sehr schlüssig, jedoch fehlt mir bei dem ersten Text der Aspekt, dass es auch die Möglichkeit gäbe Tagungen etc. auch komplett digital zu halten. Ich weiß nicht, ob der Text schon vor der Pandemie entstanden ist, wenn ja, dann hätte man das auch nicht wissen können, wie sowas aussieht, aber das spart schließlich auch Emissionen.
- Größtenteils stimme ich den Autor:innen der beiden Beiträge zu. Die Idee Webgestaltung zu reduizieren, also unter anderem effizientere Programmiersprachen zu nutzen und weniger HTML, CSS, JavaScript zu nutzen, um Datenverbrauch zu reduzieren, scheint ein guter Ansatz zu sein. Jedoch kann es dabei dazukommen, dass einige Implementierungen nicht mehr möglich werden. Außerdem ist die Benutzererfahrung dann reduziert. Dies ist aber ein größer Faktor in den DH, dass mehr Menschen nutzen von den Methoden haben unter anderem durch Mainstreaming. Zudem könnte die minimale Implementierung, die laut Autor wahrscheinlich auch mehr Aufwand ist, mehr Kosten (vor allem Personal) bedeuten. – Ansonsten finde ich die genannten Aspekte und Lösungsmöglichkeiten sehr relevant für die heutige Zeit und es ist wichtig, darauf aufmerksam zu machen.
- Den Ansatz „consider mobile-first design“ halte ich im Kontext der Digital Humanities nicht für sinnvoll. Es mag zwar stimmen, dass im Alltag häufiger über mobile Geräte auf Websites zugegriffen wird, ich kann mir jedoch nicht vorstellen das dies in der Wissenschaft auch so ist.
- Im Großen und Ganzen stimme ich beiden Artikeln zu. Ich frage mich nur, wie stark die Entwicklung von Technologien, Software etc. beeinflusst wird. Wenn man bedenkt, dass die Prinzipien des Minimal Computing die Flexibilität bei der Verwendung neuer oder bereits existierender Technologien einschränken. – Darüber hinaus, wie im Artikel erwähnt, ist Minimal Computing nicht für alle Fälle geeignet, sehr wahrscheinlich ist es in Bereichen, in denen fortgeschrittene Technologien eine entscheidende Rolle spielen, nicht sehr gut anwendbar, doch gerade in diesen Bereichen sind die Auswirkungen auf die Umwelt am größten. – Man sollte aber im Hinterkopf behalten dass, in einer Zeit, in der Umweltfragen immer drängender werden, es wichtig ist, dass Technologieentscheidungen nicht nur nach funktionalen Aspekten getroffen werden.
- Ich stelle mir die Frage, ob der Fokus auf ein “greening” der akademischen Informatik, ein sinnvoller Ansatz ist. Die breite Gesellschaft benutzt sowieso ständig digitale Mittel. Was ist der Unterschied, ob ich social media nutze, Videospiele spiele oder eine akademische Ressource besuche? Andere Bereiche, wie crypto mining, sind noch viel verschwenderischer. – Der Mythos des “ethischen Konsums” (Bsp. Individueller Carbon Footprint). In Wirklichkeit können wir als Individuen wenig an der Lage ändern. Strukturelle Probleme erfordern strukturelle/politische Lösungen. – Besserer Lösungsansatz meiner Meinung nach: Legislaturänderungen (Bsp. Höhere Steuern für übermässigen Stromkonsum, Verbote). Staatliche Förderung erneuerbarer Energie.
- Im Großen und Ganzen stimme ich den Autor:innen zu und ich verstehe den Impuls, im eigenen Verantwortungsbereich verantwortungsbewusst handeln zu wollen. Ich denke aber, dass es ganzheitlich nur einen winzigen Unterschied macht, wie Wissenschaftler:innen zu Tagungen oder Konferenzen kommen. Insbesondere, wenn die Lufthansa Leerflüge zum Beginn von Covid-19 geflogen hat, um ihre Slots nicht zu verlieren.
- Einzelne Aspekte beider Texte an sich sehe ich genau so und stimme zu. Der nächste Schritt ist aber, dass man darüber nachdenkt, wie man das umsetzen kann und welche Umsetzung realistisch ist und wie verschiedene Umsetzungsstrategien im gesamten Kontext der Realität funktionieren. Und während es nicht schwer ist, nicht unnötig dynamische Seiten zu benutzen und sich in Tools für statistische Anwendungen einzuarbeiten oder gewisse Aspekte beim Besuch von Konferenzen zu beachten, ist es ein unrealistischer Traum, effiziente Programmiersprachen Masterstudenten beizubringen, sodass sie nach dem Studium mit diesen Sprachkenntnissen auf das Arbeitsmarkt können. Oder der Umstieg auf online oder hybride Konferenzen ist für den Umweltschutz effizient, aber für die psychische Gesundheit von Wissenschaftlern wiederum nicht. Und wenn man all diese Aspekte erst nach dem Studium mitbekommt, während man arbeitet, dann soll erstmal die Möglichkeit geschaffen werden, dass die Arbeitgeber darauf Wert legen, dass Leute sich umqualifizieren, um weniger umweltschädlich zu arbeiten (und realistisch sind das mehrere Jahre vom anteiligen Bildungsurlaub), und Stand jetzt kann man sich sehr oft nicht leisten, darauf zu achten, weil man bei entscheidenden Aspekten nicht die Zeit hat, neben der Arbeit noch Qualifikationen zu erwerben, die umweltschonend sind, und kümmert sich erstmal darum, nicht gekündigt zu werden oder die Probezeit zu überstehen.
- Ein Aspekt, der unterschiedlich interpretiert oder betrachtet werden könnte, ist das Gleichgewicht zwischen individuellen und systemischen Maßnahmen im Umgang mit den Umweltauswirkungen der digitalen Geisteswissenschaften. Das Dokument betont individuelle Entscheidungen wie die Wahl umweltfreundlicherer Reisemöglichkeiten und die Teilnahme an weniger Veranstaltungen, erkennt aber auch die Notwendigkeit systemischer Änderungen bei der Organisation wissenschaftlicher Veranstaltungen an. Manche Einzelpersonen oder Gruppen geben systemischen Veränderungen den Vorzug vor individuellen Maßnahmen, während andere für einen kombinierten Ansatz plädieren, der sowohl individuelle Verhaltensweisen als auch systemische Strukturen berücksichtigt. Dieses Gleichgewicht zwischen individuellem Handeln und systemischen Veränderungen ist eine komplexe und anhaltende Diskussion im Kontext der ökologischen Nachhaltigkeit.
- Ein weiterer Aspekt ist die Abwägung zwischen minimaler Datenverarbeitung und Arbeitsaufwand. Das Dokument sagt zwar, dass Minimal Computing in einigen Fällen mehr Arbeit als Standard Computing mit sich bringen kann, betont aber, dass sich diese Arbeit lohnt, um ein länger andauerndes digitales Projekt mit minimalem Ressourcenbedarf zu gewährleisten. Einzelpersonen oder Organisationen können jedoch unterschiedliche Ansichten über das Gleichgewicht zwischen arbeitsintensiven Ansätzen und ökologischer Nachhaltigkeit haben, insbesondere im Zusammenhang mit der Ressourcenzuweisung und den Projektprioritäten.
Interessante neue Einsichten?
- Eine neue Einsicht war, dass es so einen Unterschied macht, ob die Website statisch oder dynamisch ausgelegt ist und auf wie viele Aspekte man achten kann und sollte.
- Ich fand beide Beiträge extrem interessant, da man sich ansonsten eher weniger mit den ökologischen Auswirkungen von Forschung befasst. Dass das Reisen zu z.B. Konferenzen schädlich ist, ist zum Beispiel weit bekannt, aber die Auswirkungen von ineffizientem Webhosting und maximalistischer Webgestaltung habe ich bisher noch nicht in Betracht gezogen.
- Mir war klar, das man „minimalistisch“ programmieren kann um den Energieverbrauch zu senken, aber ich hatte nicht bis zur Anzahl der Pixel einer Schriftart auf einer Website gedacht.
- Für mich war vieles neu - vor allem wie weitreichend „Greening DH“ gedacht werden kann und wie vielfältig die Aspekte sind, die dazu beitragen können, Forschungspraktiken in den DH mehr oder weniger umweltfreundlich zu gestalten. Überrascht hat mich zum Beispiel, dass sogar Aspekte wie die Wahl der Programmiersprache oder der Fonts auf Webseiten einen Einfluss haben können (wobei es mir nicht ganz leicht fällt einzuordnen, wie relevant oder ausschlaggebend diese Aspekte vllt. im Vergleich zu anderen Faktoren sein könnten).
- Ich habe nie darüber nachgedacht, dass allein die Programmiersprache, die ich benutze, einen Einfluss auf die Umwelt haben kann. Ich finde es wirklich sehr erstaunlich, wie viele Bereiche, Wege und Möglichkeiten es gibt, die man nicht kennt, um eine umweltfreundliche Entscheidung zu treffen.
- Zumindest die Reflexion über Nachhaltigkeit in der Informatik allgemein finde ich sinnvoll. Low Tech Ansätze können auch praktische Vorteile für die Entwickler und Nutzer haben (Bsp. Ladezeiten).
- Interessant war für mich die Einsicht, dass schon die genutzte Programmiersprache Auswirkungen auf die Klimabilanz der Forschung hat. Mir war nicht bewusst, dass die Programmiersprachen so unterschiedlich in den Bereichen Zeit, Energie und Speicher performen. Wieso wird dann Python immer noch vorzugsweise genutzt? Hat es für die DH so viele Vorteile im Vergleich zu den anderen Sprachen? Die Werte von C waren besonders gut. Könnte man auch C für die DH nutzen, oder gibt es da klare Nachteile im Vergleich zu Python? – Ich fand außerdem interessant, dass das Manifest von Baillot et al. scheinbar noch nicht so alt ist, obwohl mir die Aussagen ziemlich grundlegend/“basic” vorkommen. Da fragt man sich, wie lange bereits in der DH über den Impact von digitalen Technologien auf den Klimawandel diskutiert wird? Scheinbar noch nicht so lange?
- Mir war es nicht bewusst, dass es dynamische und statische Seiten gibt, und generell vor diesem Masterstudium war mir nicht bewusst, WIE VIEL Speicherplatz Sachen benötigen, die an manchen Webseiten angezeigt werden, und dass man so viel Hardware mit jeweils unterschiedlichen Feinheiten braucht, was wiederum Geld kostet und umweltschädlich ist. Vor dem Studium habe ich mir das einfacher vorgestellt oder nicht nachgedacht, was genau alles es auf sich hat.
- Eine interessante Erkenntnis aus der Lektüre ist die Überschneidung der digitalen Geisteswissenschaften mit ökologischer Nachhaltigkeit und sozialer Gerechtigkeit. Das Manifest hebt die Verflechtung der Arbeit der digitalen Geisteswissenschaften mit der Klimakrise hervor und betont die Verantwortung der digitalen Geisteswissenschaftler, als Reaktion auf die ökologischen Herausforderungen zu handeln.
Sitzung 13 (5. Feb. 2024)
Abschluss
Überblick
- Rückblick auf die “Einführung in die DH”
- Das erste Fachsemester in der Gesamtschau
- Feedback im Cryptpad