Linked Open Data for Literary History
22 Nov 2024
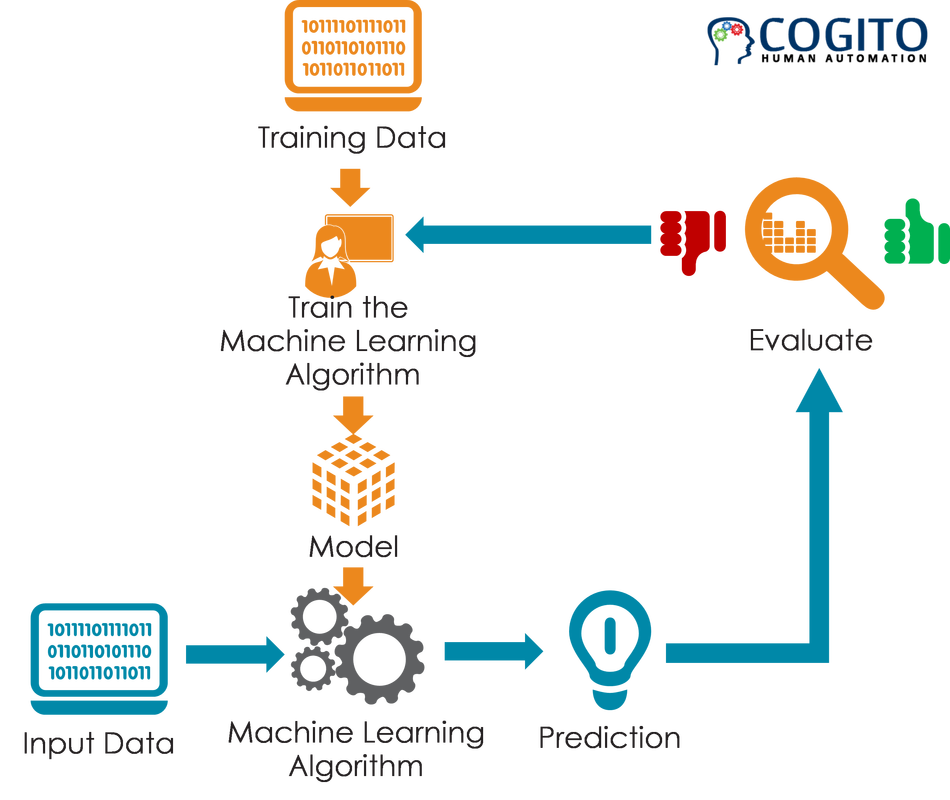
What is TDM / Machine Learning?
- Fundamentally, ML involves detecting relations between features and labels
- Features: simple properties that we can observe in texts (e.g.: word forms)
- Labels: more complex phenomena that are relevant to our research (e.g.: direct speech or metaphors)
- We use this approach primarily for information retrieval
- We start with a text collection
- We may annotate part of the data with labels
- Then train a new model, or use an existing model
- Evaluate the performance of the model on the annotated data
- And then derive labels from unannotated text
What is Linked Open Data?
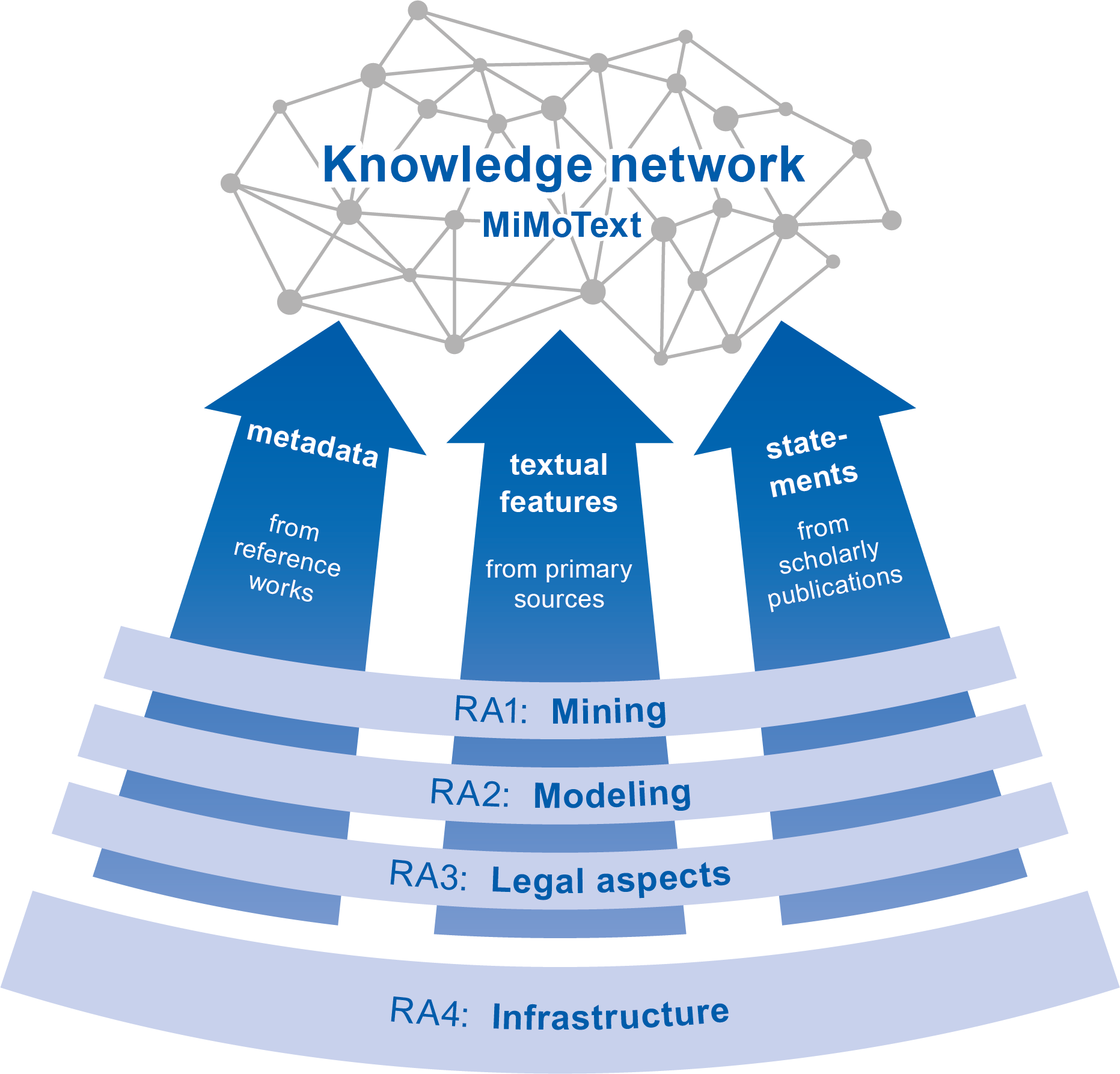
Overview of Mining and Modeling Text
Pillar 1: Bibliographie du genre romanesque français

Pillar 2: primary literature (novels)
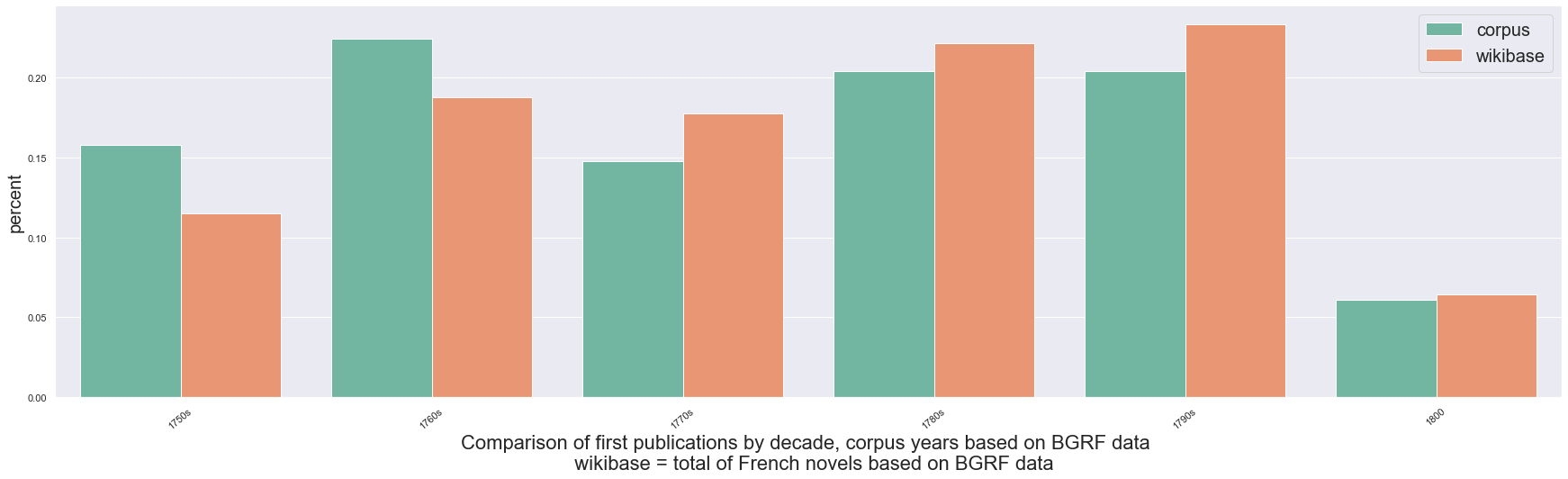
- Corpus of 200 French novels (1750-1800)
- Encoding: in XML-TEI, with metadata, according to ELTeC schema
- Methods of analysis: Topic modeling, NER, stylometry, etc.
Pillar 3: Scholarly Literature
- Corpus of chapters from literary histories about the French Eighteenth-Century novel
- Annotation guidelines => Manual annotations (using INCEpTION)
- Linking of INCEpTION with MiMoTextBase and Wikidata => disambiguation
- Creation of statements about authors and works (genres, themes, etc.)
- Machine Learning based on the annotated training data
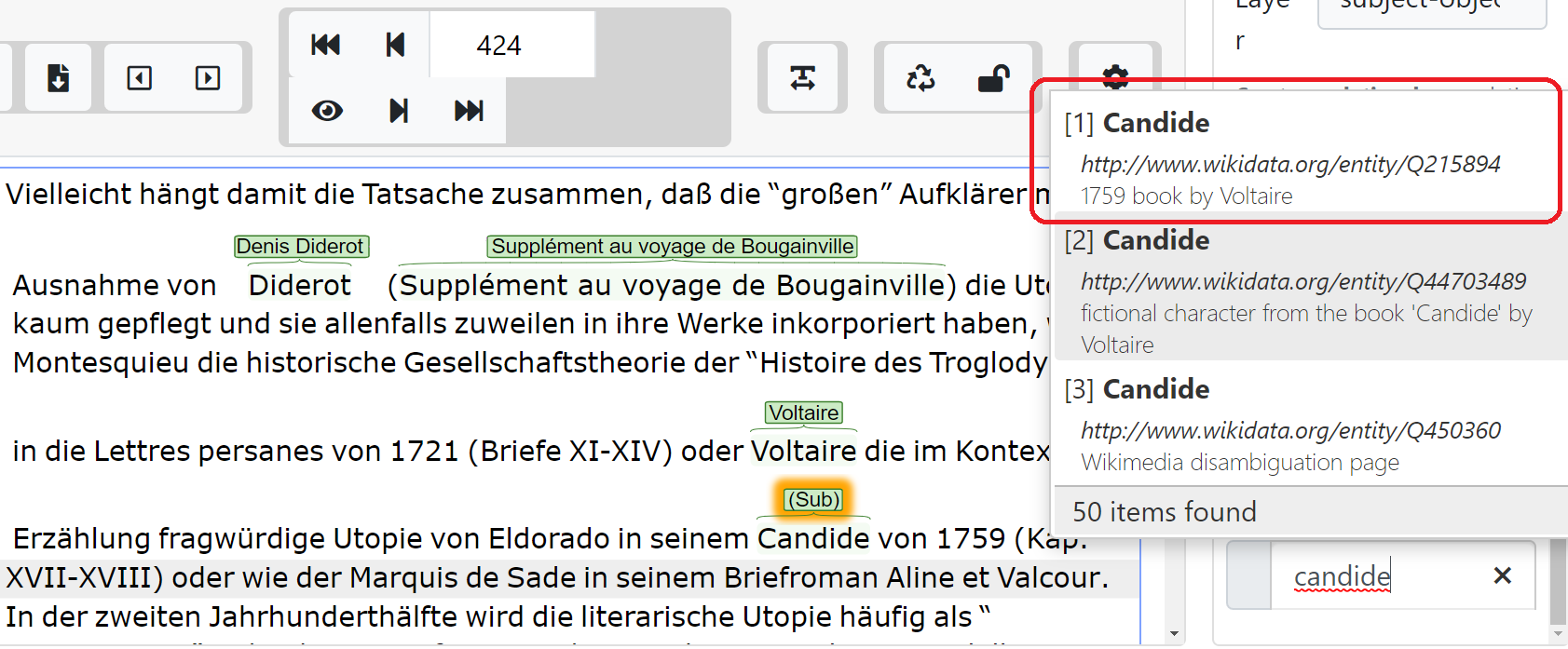
Example: The module on themes
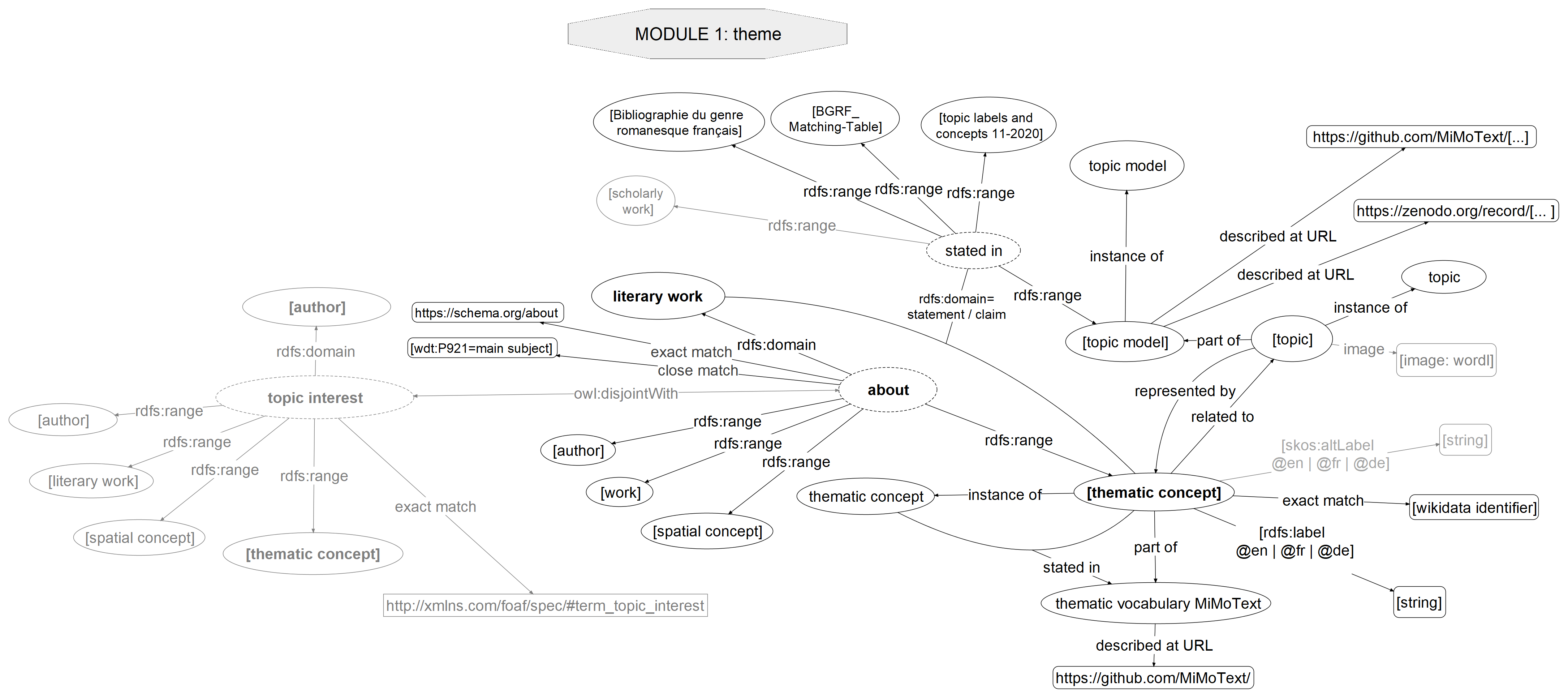
Linking with Wikidata for ‘federated queries’
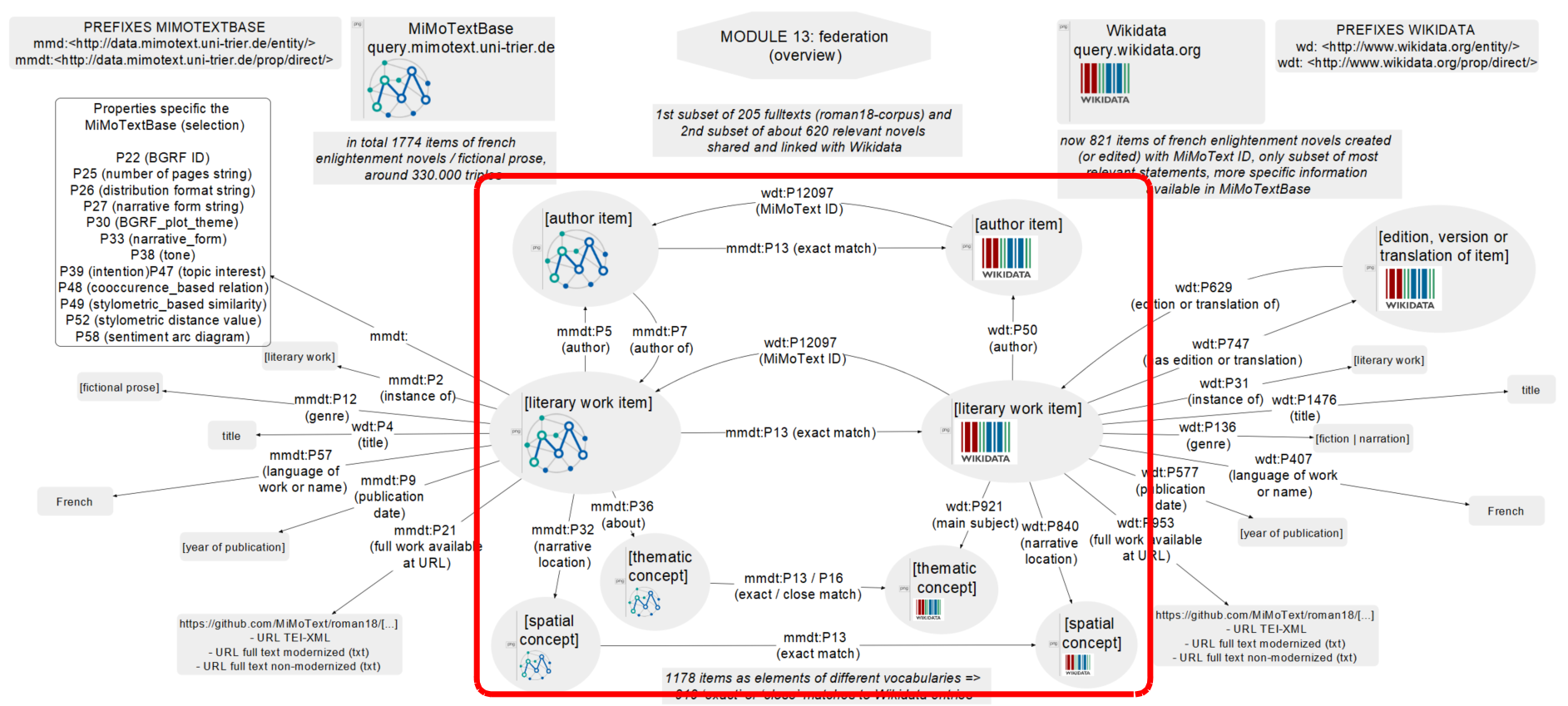
Result: The MiMoTextBase
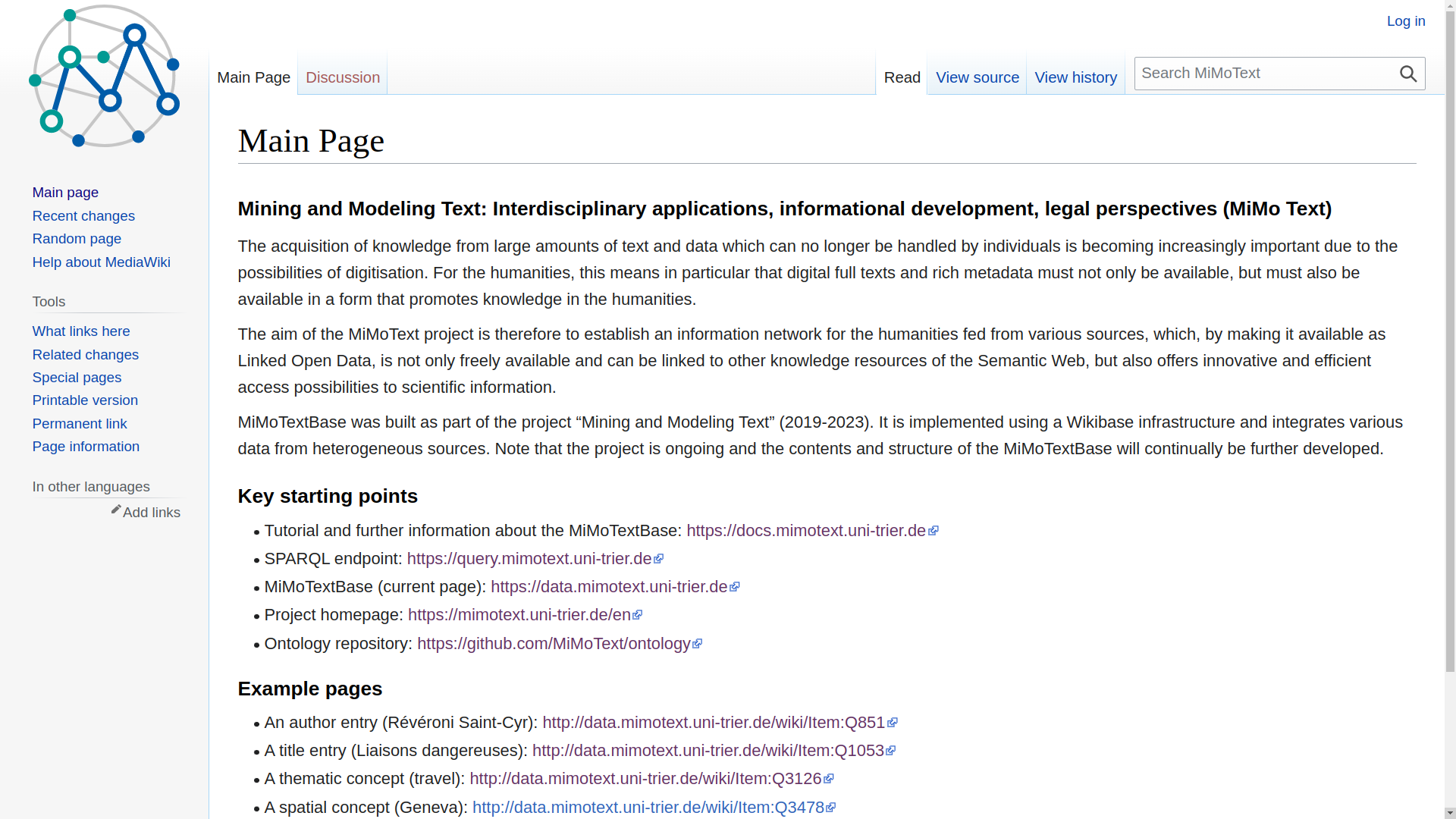
SPARQL endpoint
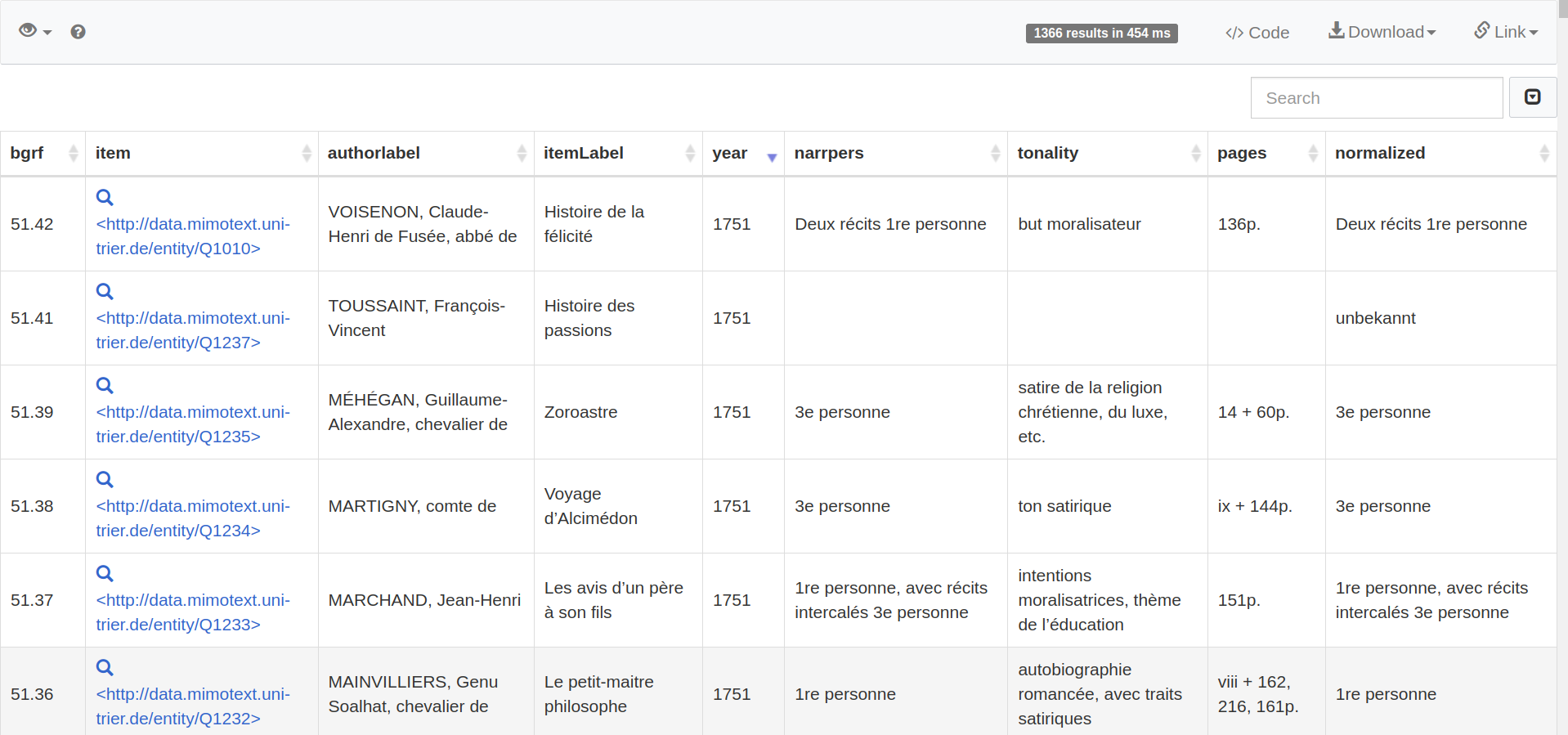
The issue: Is there a libertine epistolary novel after 1782?
- Is there libertinage in the epistolary novel after 1782?
- van Crugten-André (1997): “the epistolary genre is hardly represented in the libertine novel after Laclos [=1782]”.
- Benoît Melançon (2004): article on the “late libertine epistolary novel”, where he speaks about 8 libertine epistolary novels from after 1782.
- Consensus on the fact that the “libertine epistolary novel” is a subgenre
- But lack of clarity on its exact temporal extension

Clarification? Data from the MiMoTextBase
- Number of novels for 1782-1800 => 647 (Q1)
- Of those, number of epistolary novels => 91 (Q2)
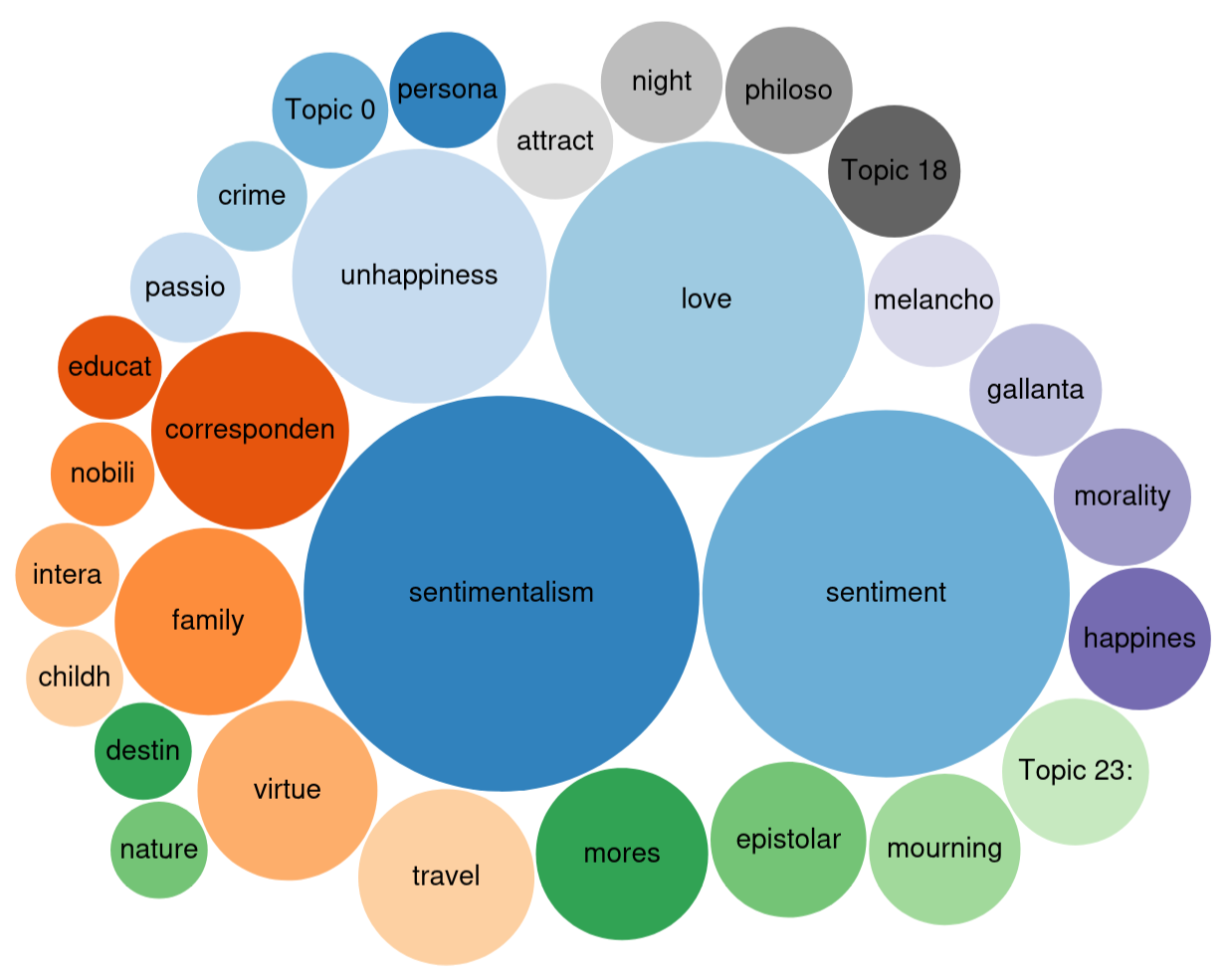
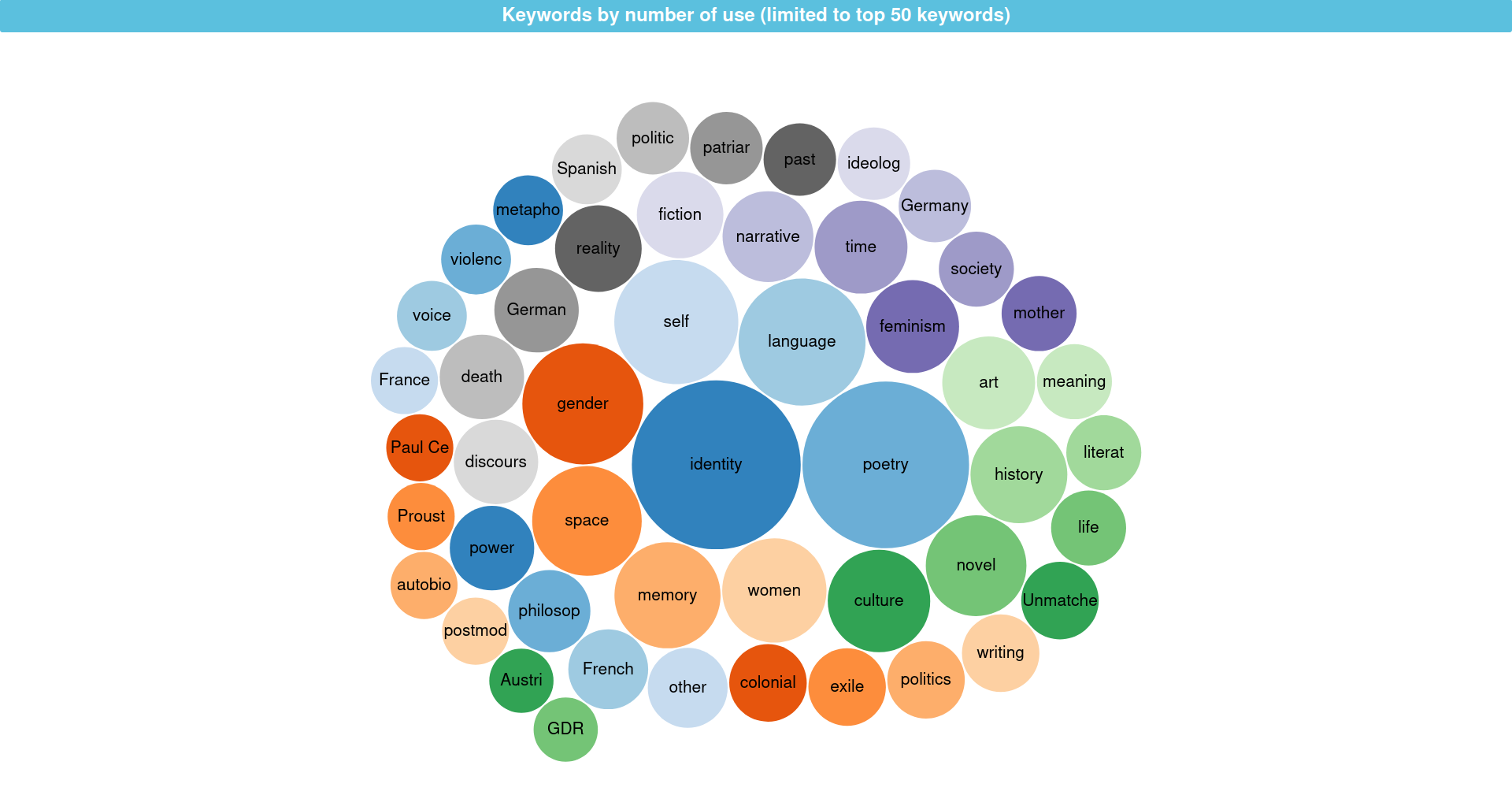
- What are their topics? => (Q3, bubble chart)
- Of those, number about libertinage? => 1 (Q4a)
- With looser definition of epistolary? => 3 (Q4a)
- Number of libertine non-epistolary novels? => 14 (Q5)
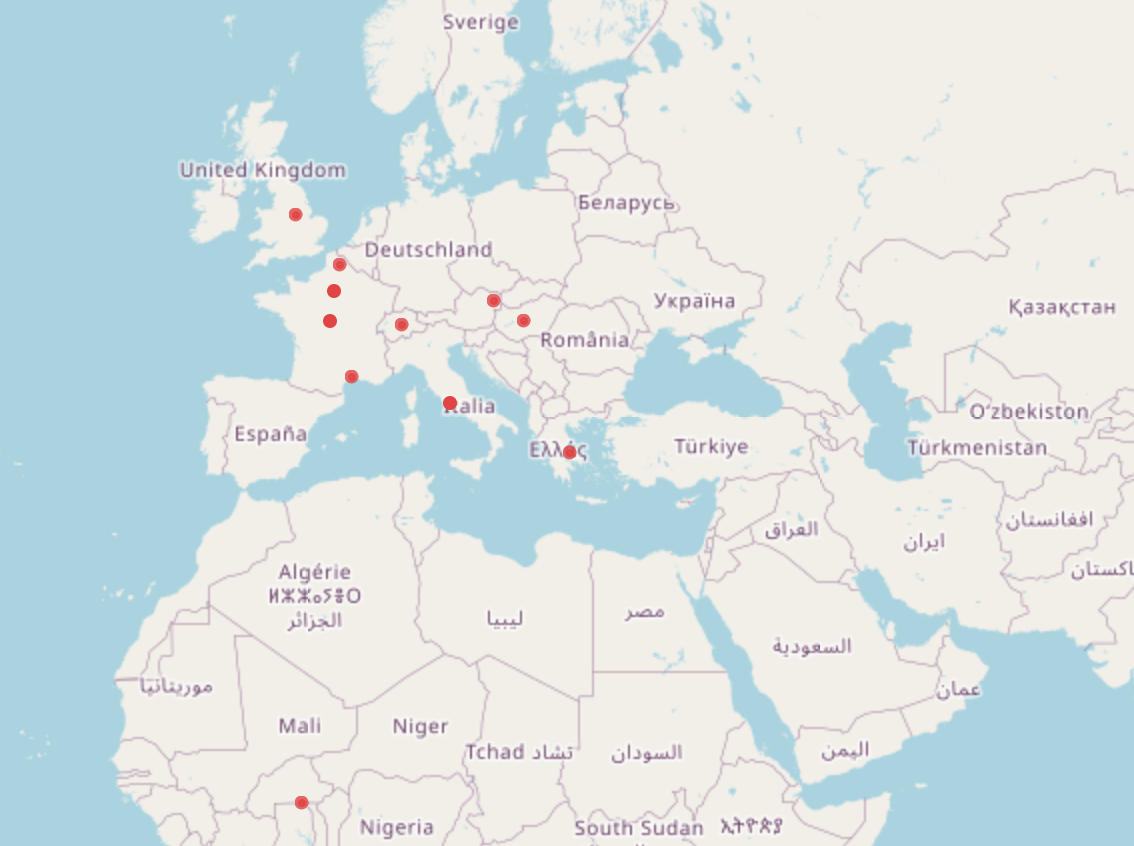
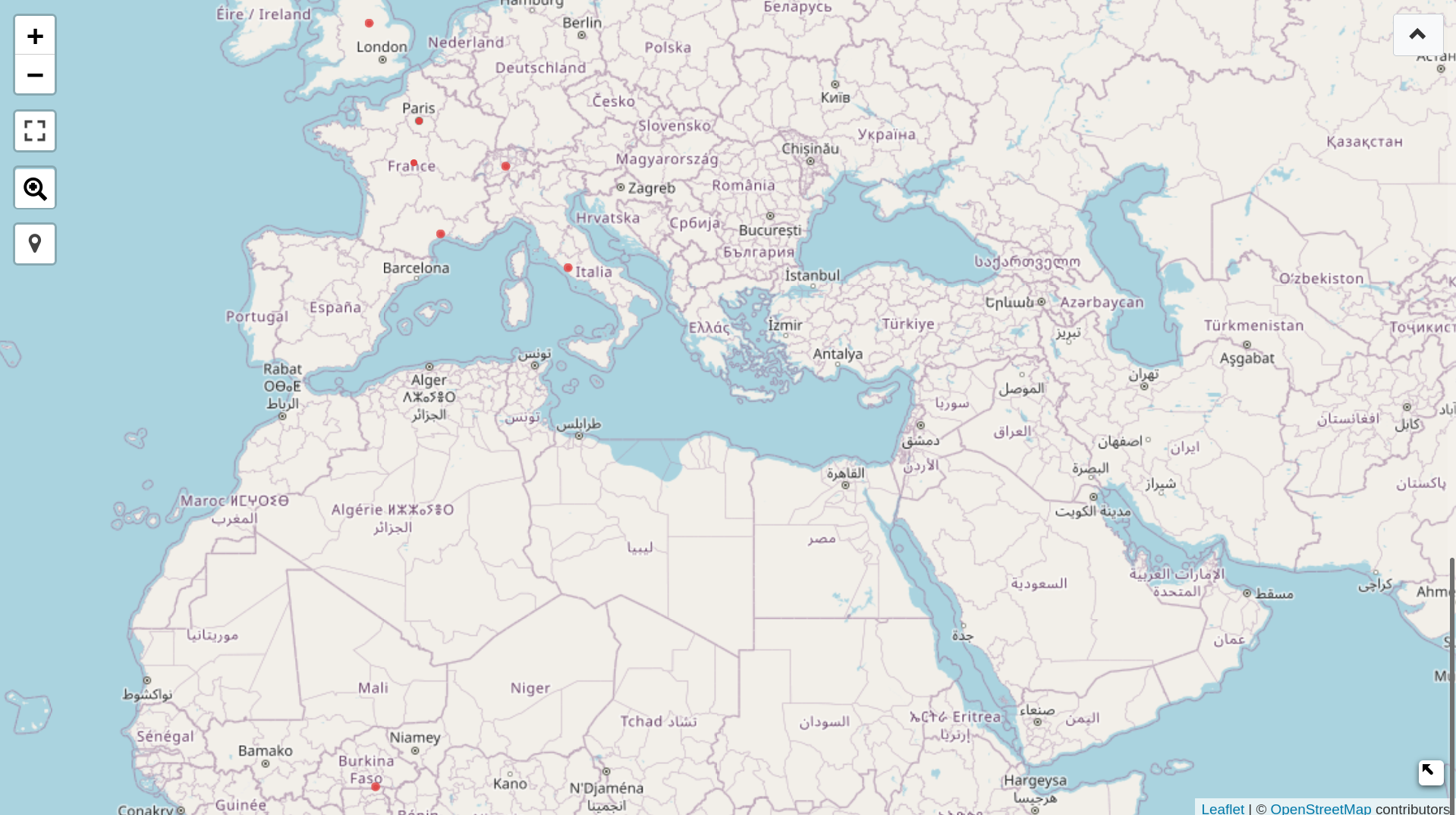
- Where do these novels take place? (Q6, federated!)
- Compared to Melançon
- Some are not marked ‘epistolary’
- Some are not marked ‘libertine’
- Two are missing
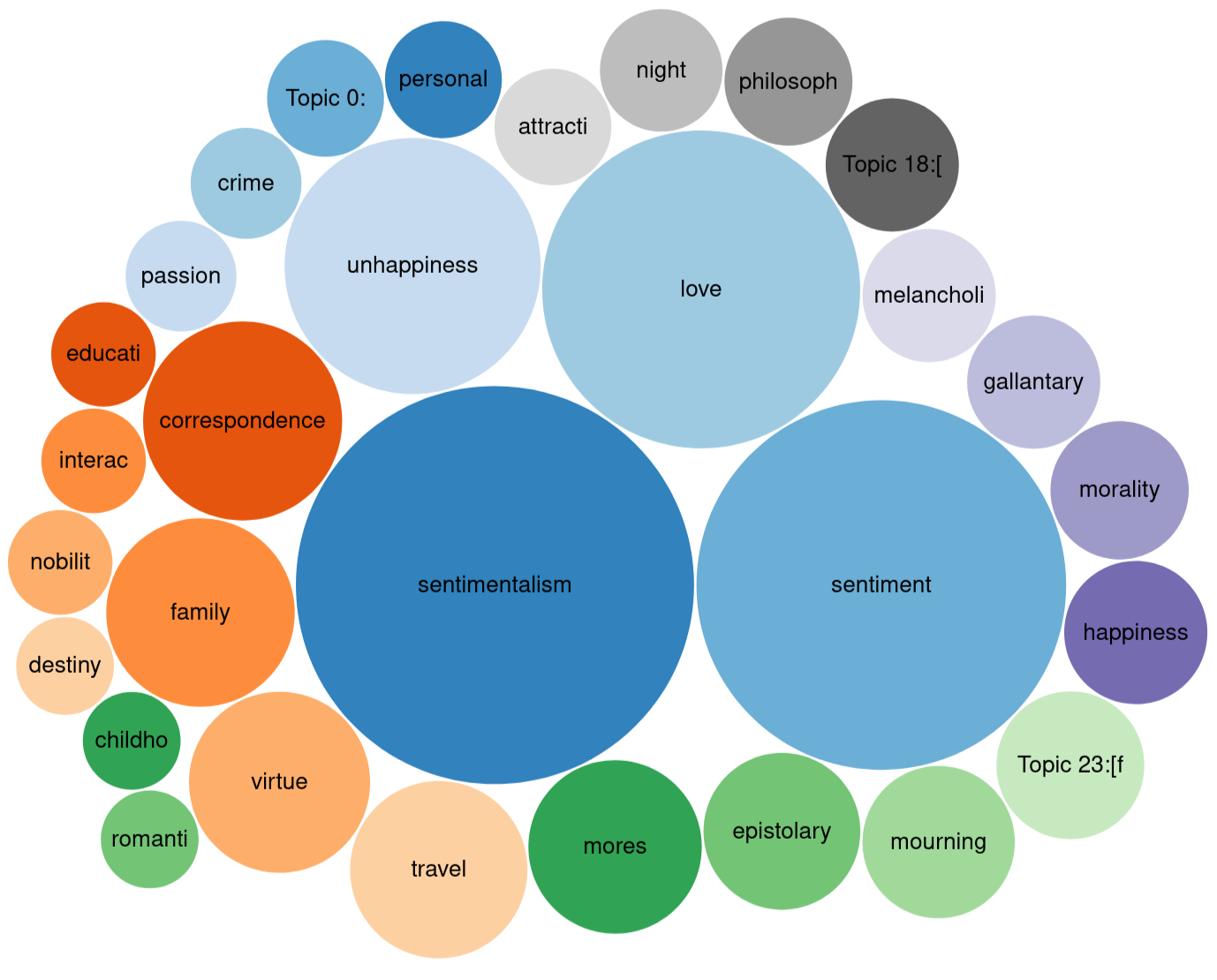
Query 3: Topics of epistolary novels post-1782
Query 6: Narrative location of libertine novels post-1782
Outlook: LOD for other domains in the Humanities

Sample queries: comparative queries
- Themes from topic modeling compared to themes in BGRF
- Themes from BGRF vs. Topic Modeling (in one query)
![]()