Towards Computational Comparative
Literary Studies
Adressing the Challenges of Multilingualism
25 May 2024
Multilingualism and me
The COST Action ‘Distant Reading for European Literary History’

The ‘European Literary Text Collection’ (ELTeC)
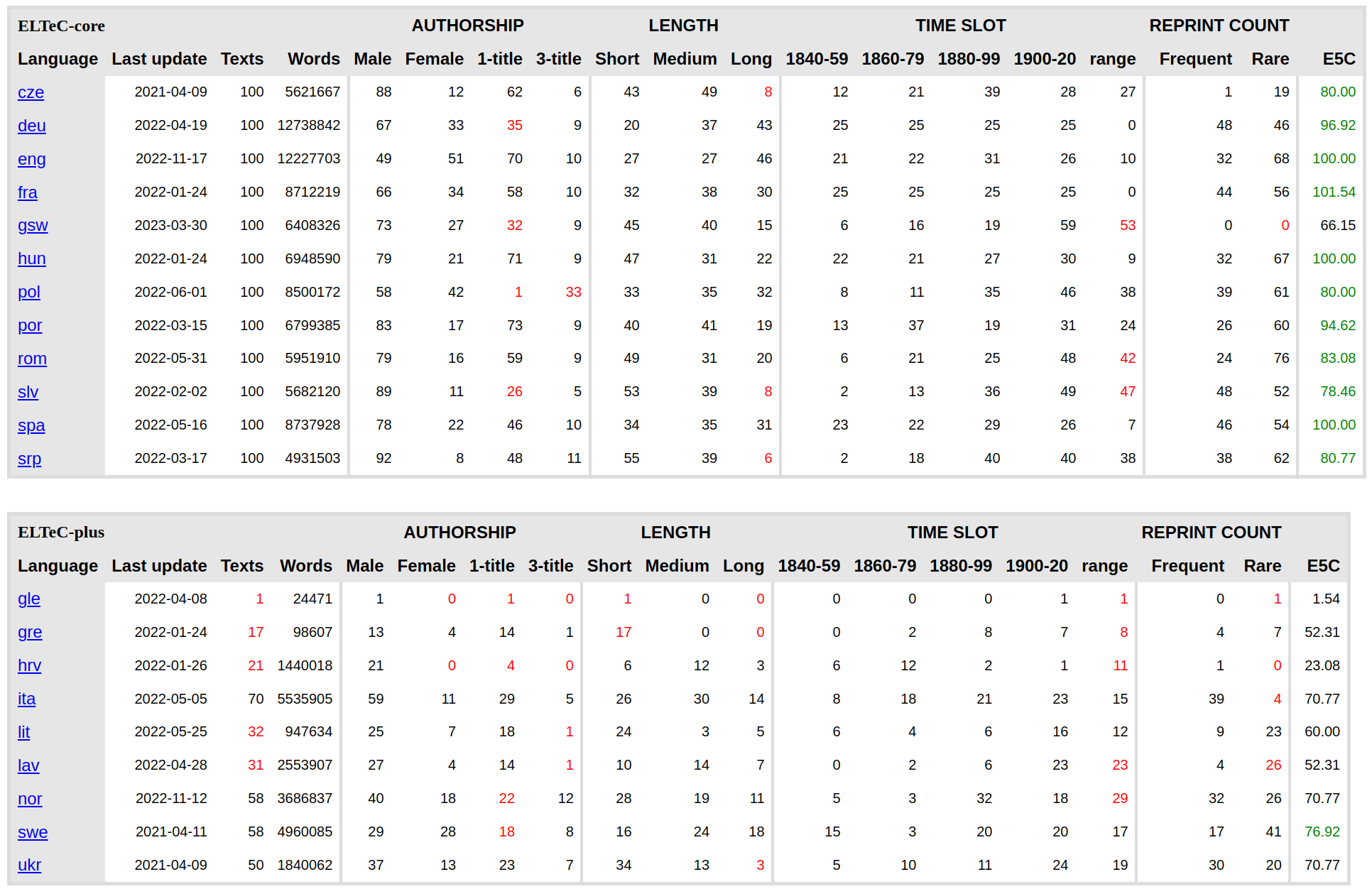
A closer look: corpus composition in ELTeC
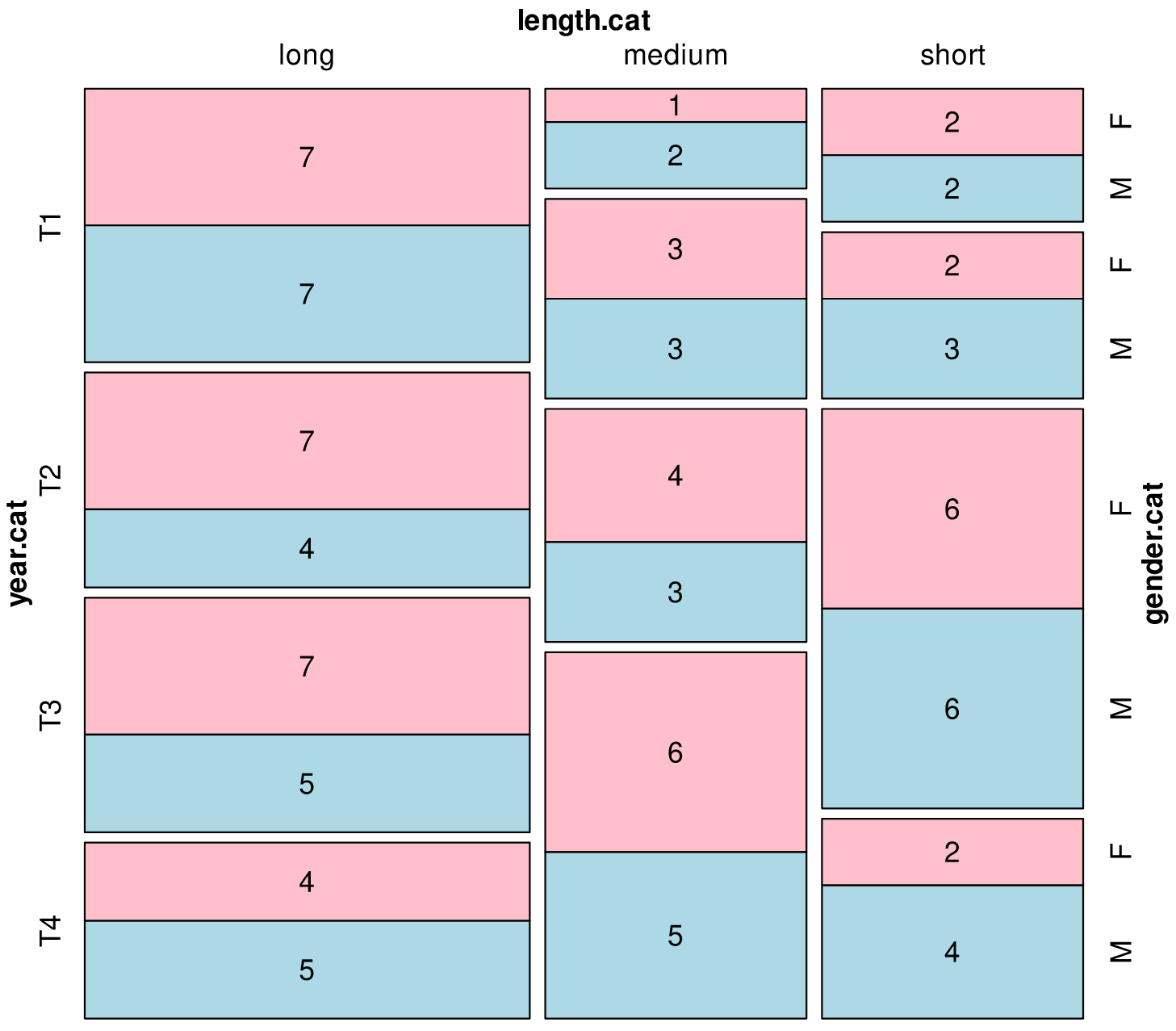 English ELTeC corpus
English ELTeC corpus
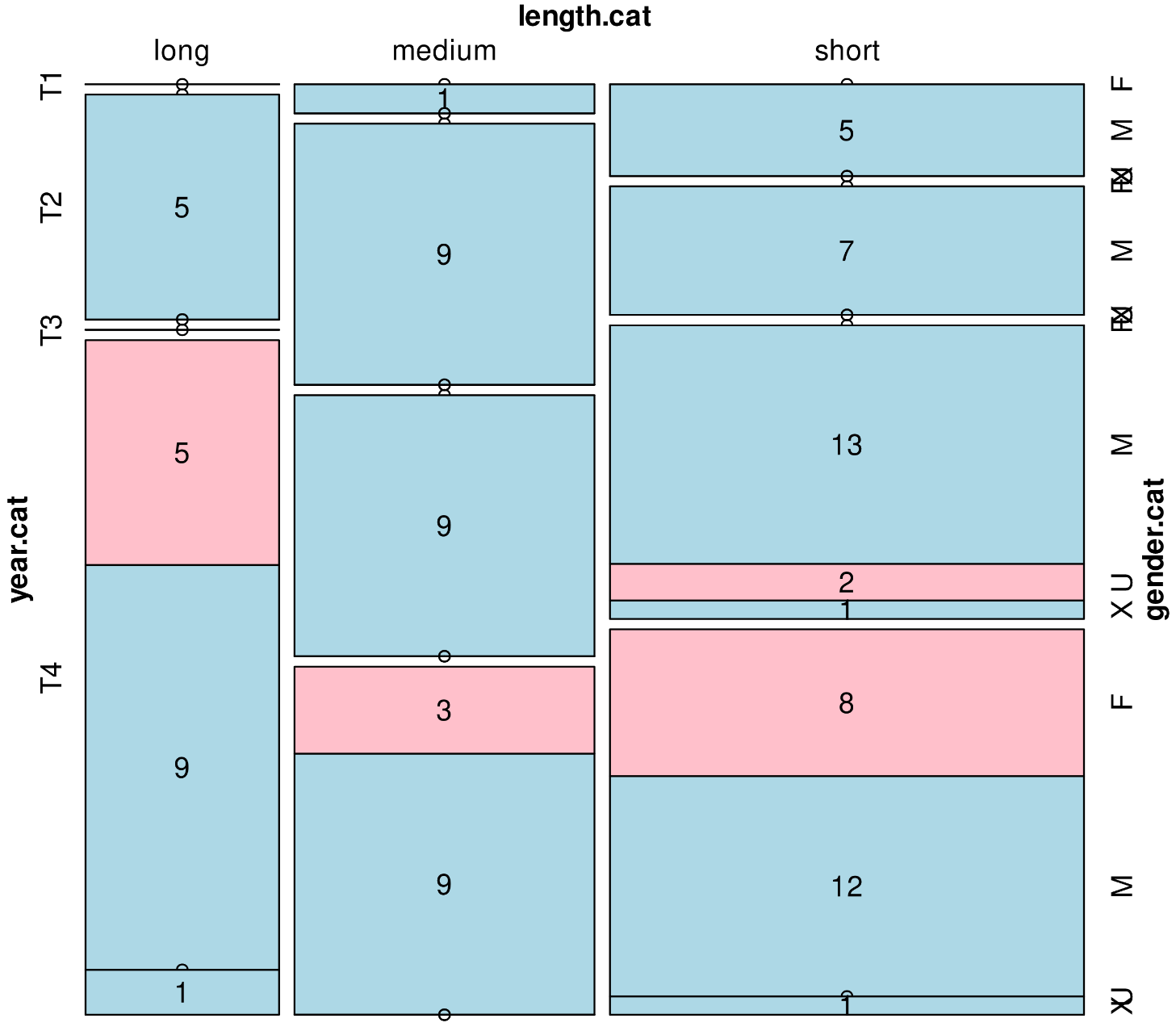 Romanian ELTeC corpus
Romanian ELTeC corpus
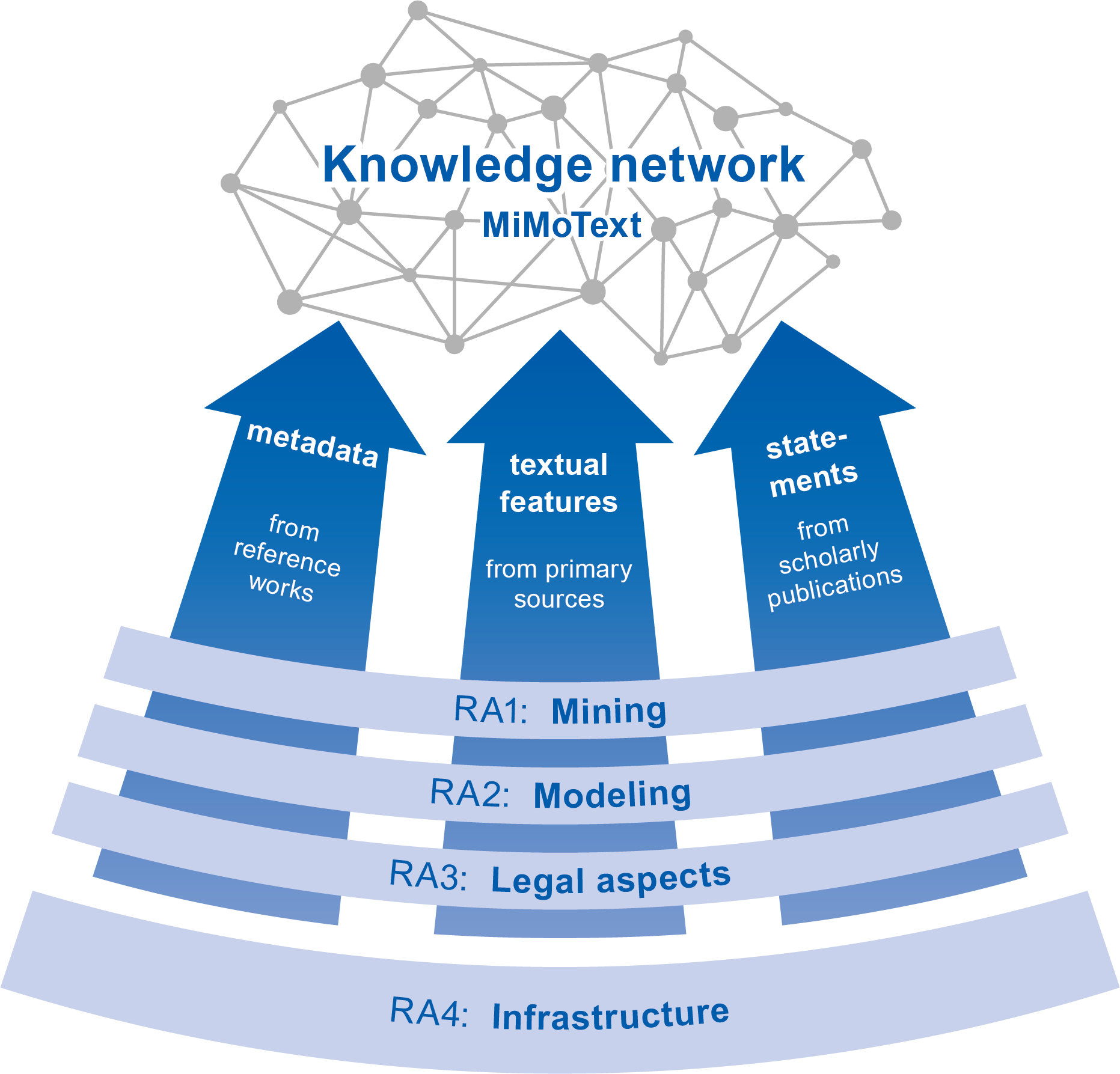
The project ‘Mining and Modeling Text’
Linked Open Data: Simple Statements
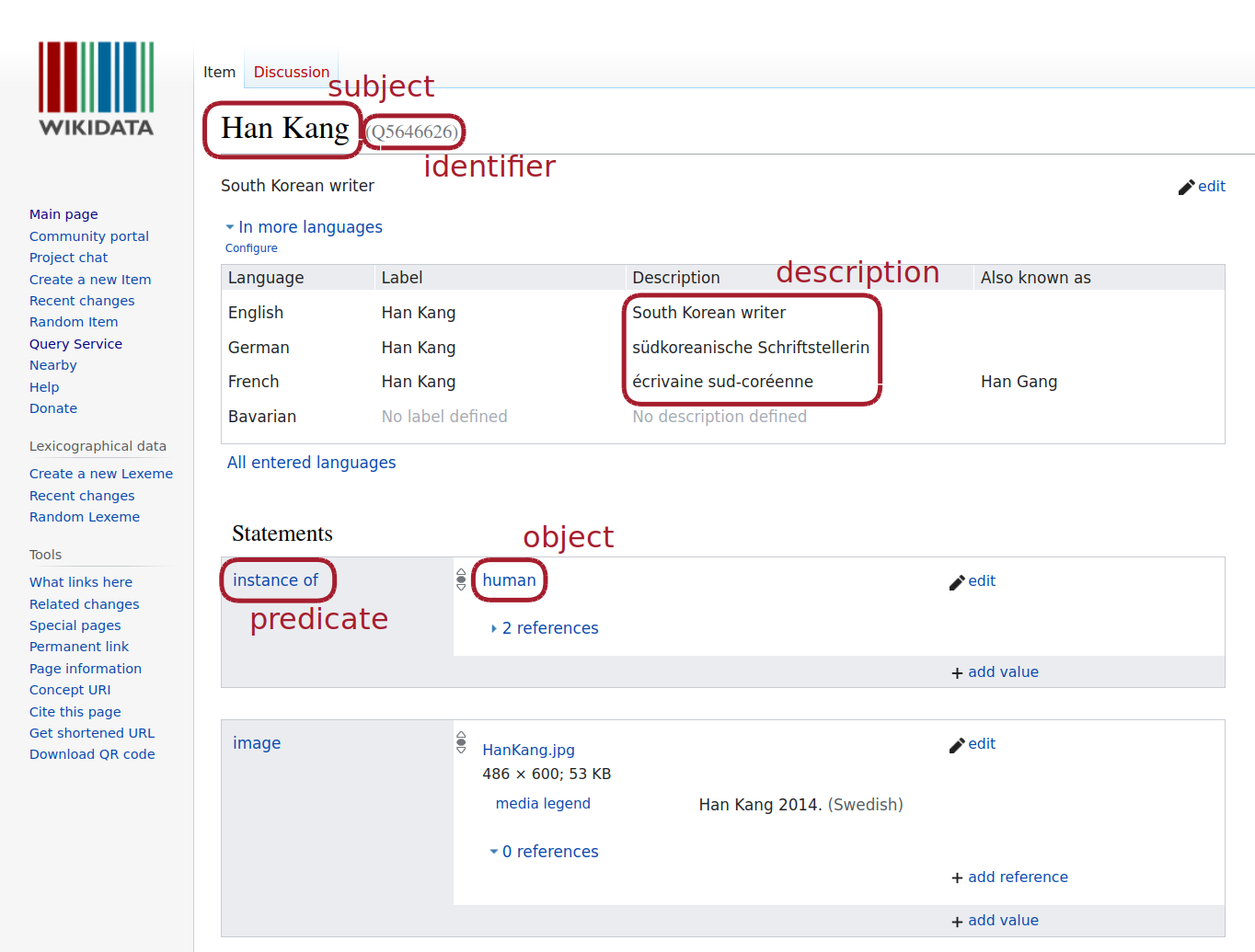
Linked Open Data: Multilingualism
MiMoText Base: Query for themes in novels



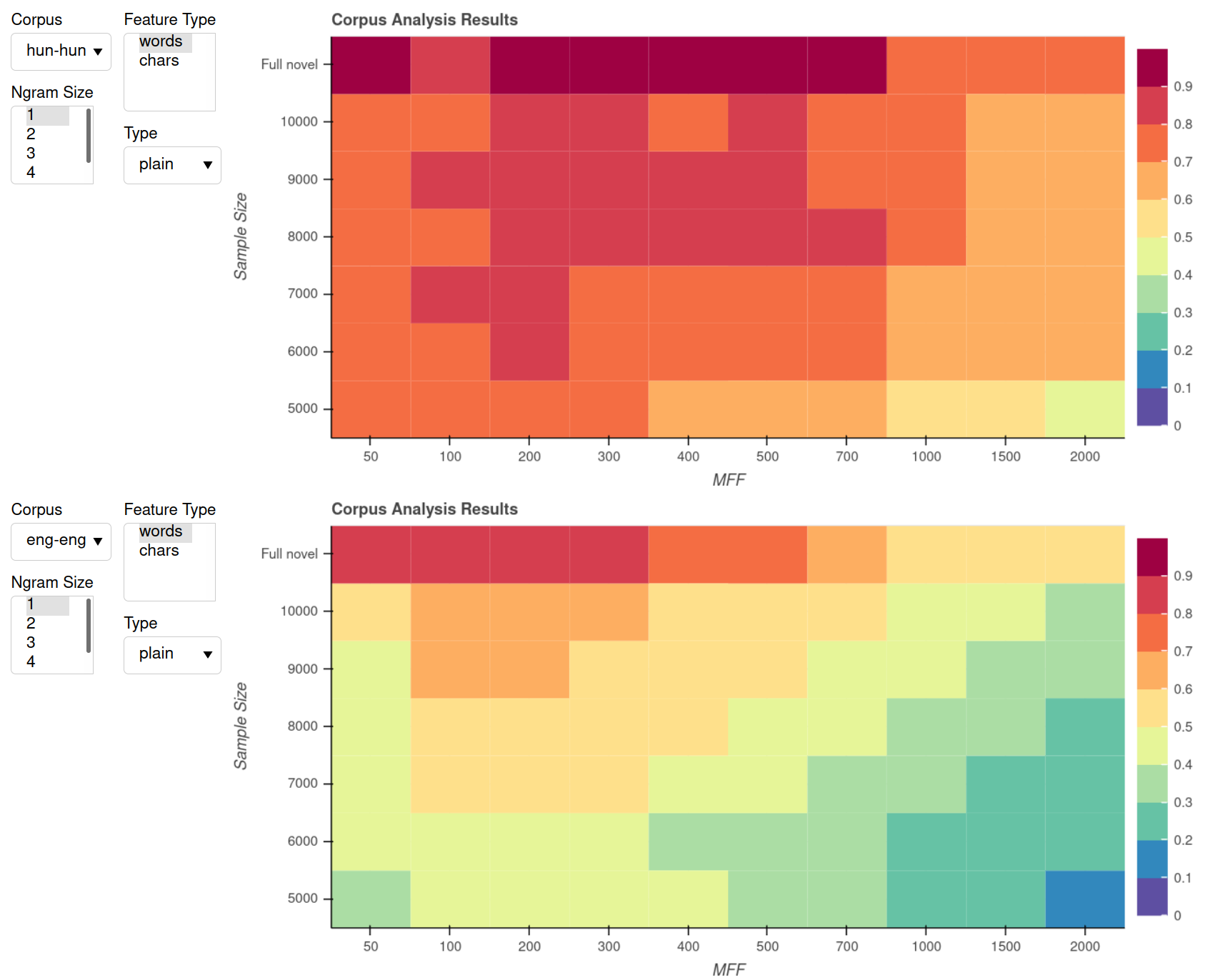
High-profile cases of stylometric authorship attribution




Some first results
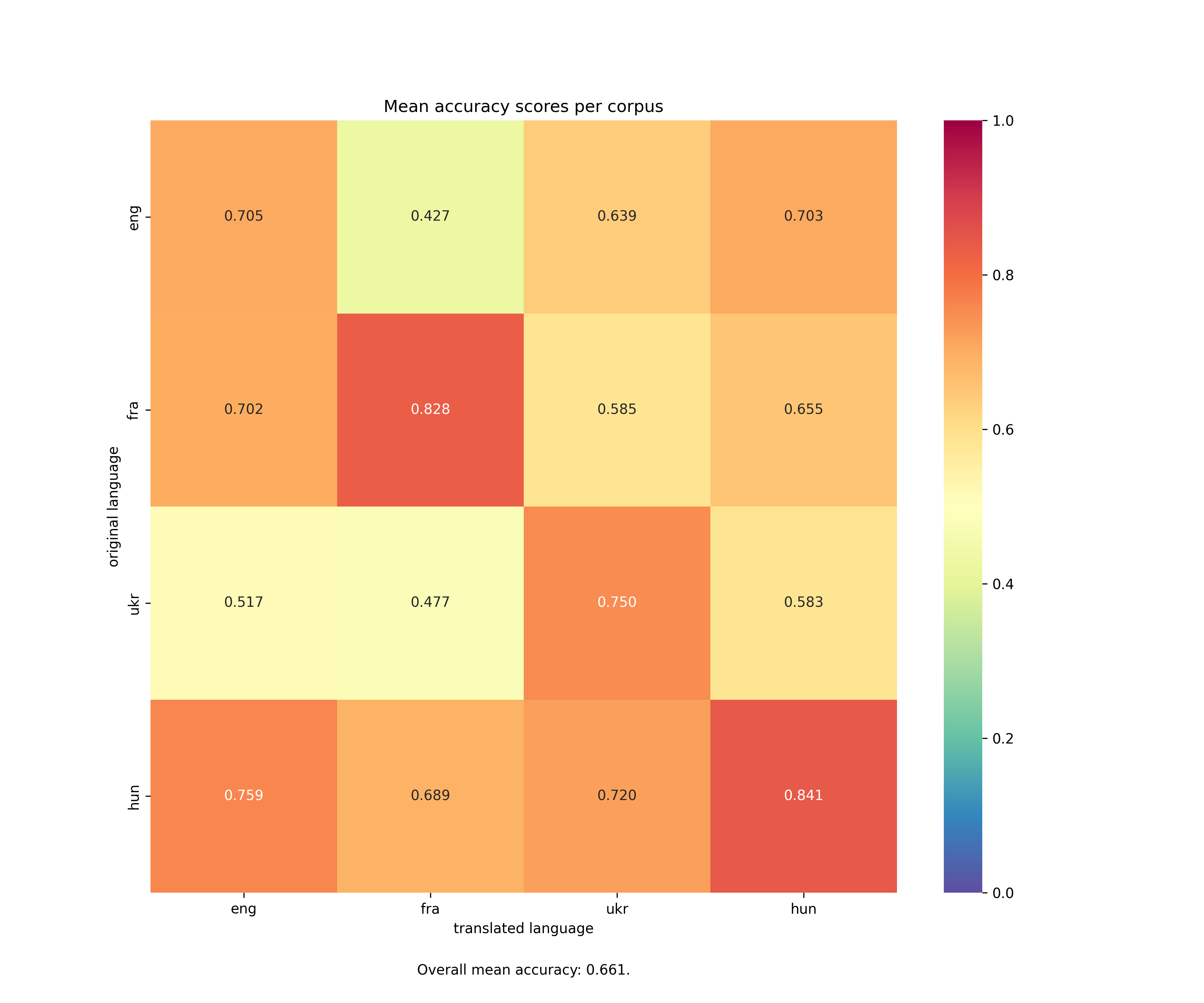
More information: Dudar et al. (in progress).
Full interactive showcase
References
![]()
Cafiero, Florian, and Jean-Baptiste Camps. 2019. “Why Molière Most Likely Did Write His Plays.” Science Advances 5 (11): eaax5489. https://doi.org/10.1126/sciadv.aax5489.
Craig, Hugh, and Arthur F. Kinney. 2009. Shakespeare, Computers, and the Mystery of Authorship. Cambridge University Press.
Dudar, Julia, Evgeniia Fileva, Artjoms Šeļa, and Christof Schöch. in progress. “Multilingual Stylometry: The Influence of Corpus Composition and Language on the Performance of Authorship Attribution Using Corpora from the European Literary Text Collection (ELTeC).” Tbc, in progress.
Juola, Patrick. 2015. “The Rowling Case: A Proposed Standard Protocol for Authorship Attribution.” Digital Scholarship in the Humanities 30 (suppl. 1): 100–113. https://doi.org/10.1093/llc/fqv040.
Schöch, Christof, Maria Hinzmann, Julia Röttgermann, Katharina Dietz, and Anne Klee. 2022. “Smart Modelling for Literary History.” International Journal of Humanities and Arts Computing 16 (1): 78–93. https://doi.org/10.3366/ijhac.2022.0278.
Schöch, Christof, Roxana Patras, Tomaž Erjavec, and Diana Santos. 2021. “Creating the European Literary Text Collection (ELTeC): Challenges and Perspectives.” Modern Languages Open, no. 1: 25. https://doi.org/10.3828/mlo.v0i0.364.
Tuzzi, Arjuna, and Michele A. Cortelazzo, eds. 2018. Drawing Elena Ferrante’s Profile: Workshop Proceedings. Padova: Padova UP.