Comparing Comparisons
Evaluating Measures of Keyness or Distinctiveness in Computational Literary Studies
Christof Schöch
(Trier University, Germany)
Kyungpook National University
Daegu, South Korea
22 May 2024
Introduction
Thanks
![]()
![]()
Sujin Kang and Heejin Kim of Kyungpook National University, as well as KADH (Korean Association for Digital Humanities).
![]()
Funding from the German Research Foundation (DFG), who has been funding this research (Zeta and Company, 2020-2023, Beyond Words, 2024-2026)
![]()
Thanks to all the project contributors: Keli Du, Julia Dudar, Cora Rok, Julia Röttgermann, Julian Schröter.
Overview
What is keyness all about?
Some recent findings in my work in CLS1
- The average sentence length in English-language novels in the period 1920–1939 is 18.9 words.
- In adventure novels by Arthur Conan Doyle, the ‘hunting’-topic has a probability of 0.38.
- The average word frequency of the word “et” (and) in French crime fiction author Maurice Leblanc is 2.65.
Sentence length in English-language novels
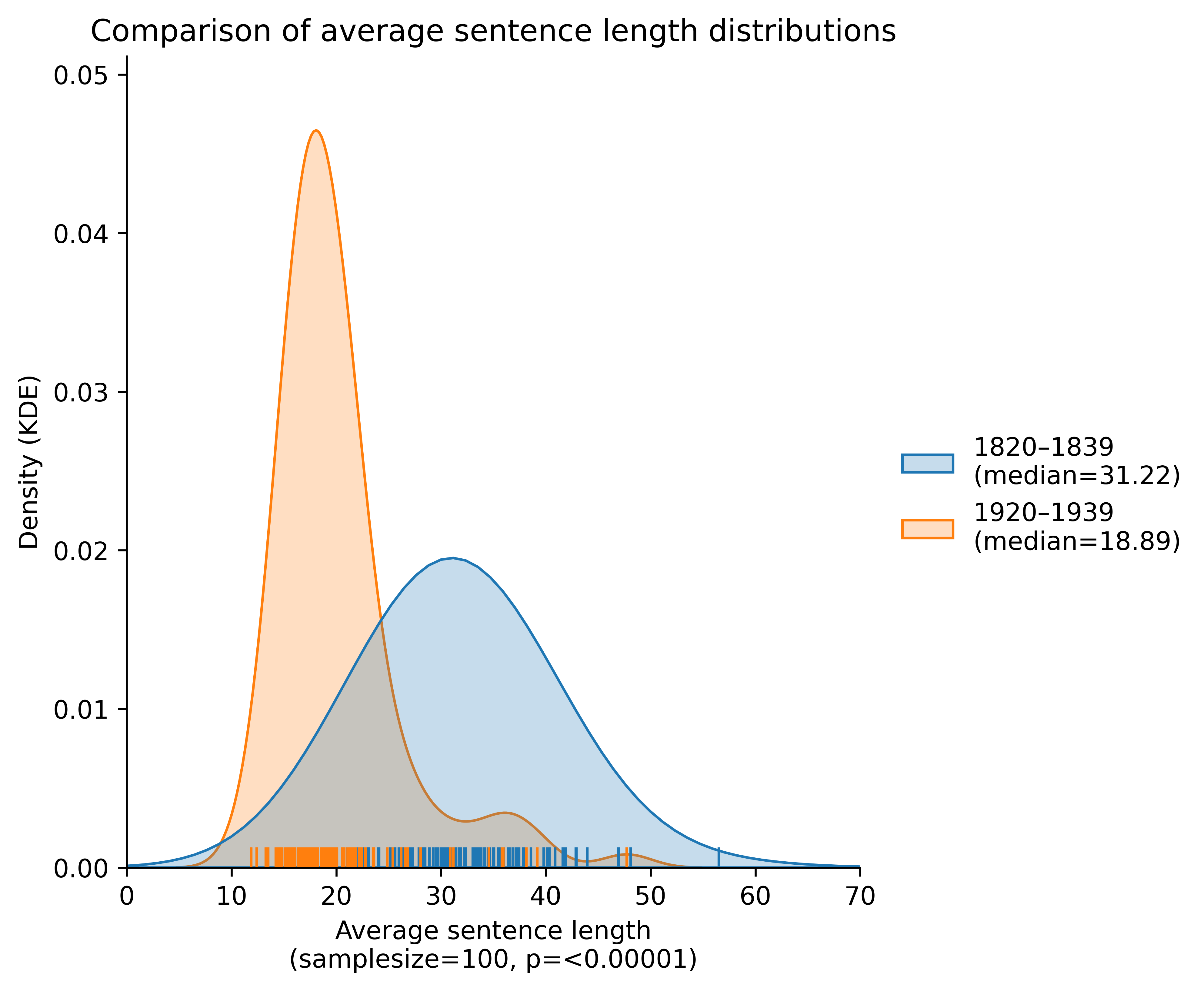
Source: dragonfly.hypotheses.org/1152
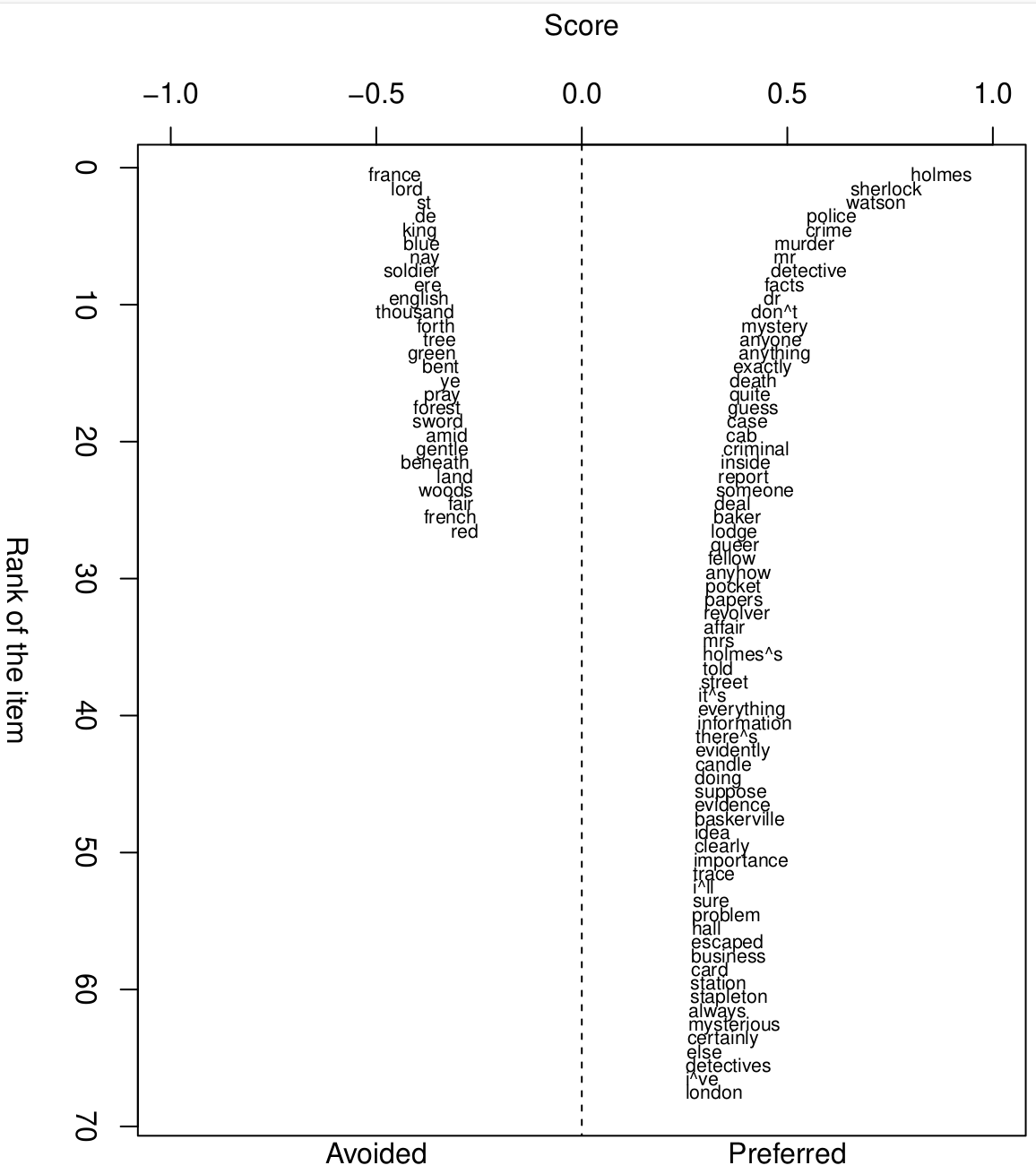
Topics in Arthur Conan Doyle
Source: dragonfly.hypotheses.org/1219
Word-frequency in Maurice Leblanc
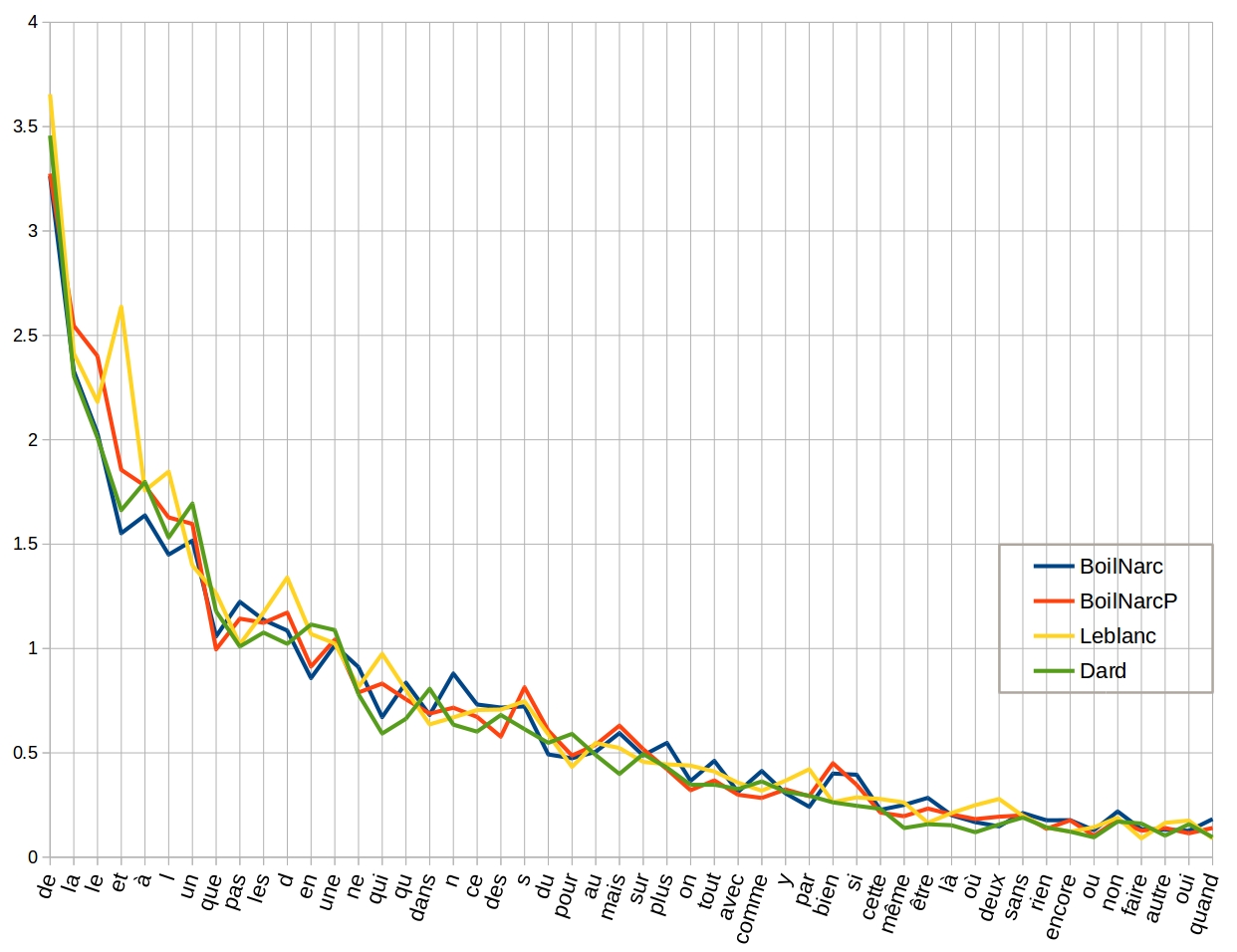
Source: dragonfly.hypotheses.org/745
Definitions: Keyness / Distinctiveness
Traditional definition of keyness
- Purely quantitative sense: A keyword is “a word which occurs with unusual frequency […] [in a document or corpus] by comparison with a reference corpus”. (Scott 1997)
![]()
What is Distinctiveness? (Schröter et al. 2021)
- (A) Logical vs. statistical sense
- Purely logical: A feature is distinctive of corpus A if its presence in a document D is a necessary and sufficient condition for D to belong to A and not to B.
- Statistical: A feature is distinctive of corpus A if it is true that, the higher its keyness in document D, the higher the probability that D is an instance of A and not of B.
- (B) Salient vs. agnostic
- Salient: A feature is distinctive iff it is noticed by readers (for confirming or violating their expectations)
- Agnostic: A feature can be distinctive without being salient in the above-mentioned sense.
- (C) Qualitative vs. no qualitative content
- Qualitative content: A feature is distinctive iff it expresses e.g. aboutness or stylistic character (=> interpretability)
- No qualitative content: A feature can be key regardless of qualitative content (=> discriminatory power)
Various keyness measures (Du et al. 2022)
- Ratio of relative frequencies
- TF-IDF
- Chi-squared test
- Log-likelihood ratio test
- LLR effect size – (Evert 2022)
- Welch’s t-test
- Wilcoxon rank-sum test
- Burrows Zeta – (Burrows 2007)
- Log-Zeta – (Schöch et al. 2018)
- Eta (difference of DP) – (Gries 2008; Du et al. 2021)
History: Keyness in CLS
Burrows’ Zeta in Authorship Attribution
- The key publication is: John Burrows, “All the way through” (Burrows 2007)
- He proposed to use Zeta in the context of authorship attribution
- Zeta is calculated as the difference of the document frequencies of a feature in two contrasting sets of documents, where the documents are segments of full texts.
- Zeta: “A simple measure of [an author’s] consistency in the use of each word-type.” (=> dispersion)
- Focuses “on a single author and seek[s] to identify which of many texts are most likely to be his or hers.” (=> authorship attribution)
Zeta for Authorship Attribution: Shakespeare (Craig and Kinney 2009)
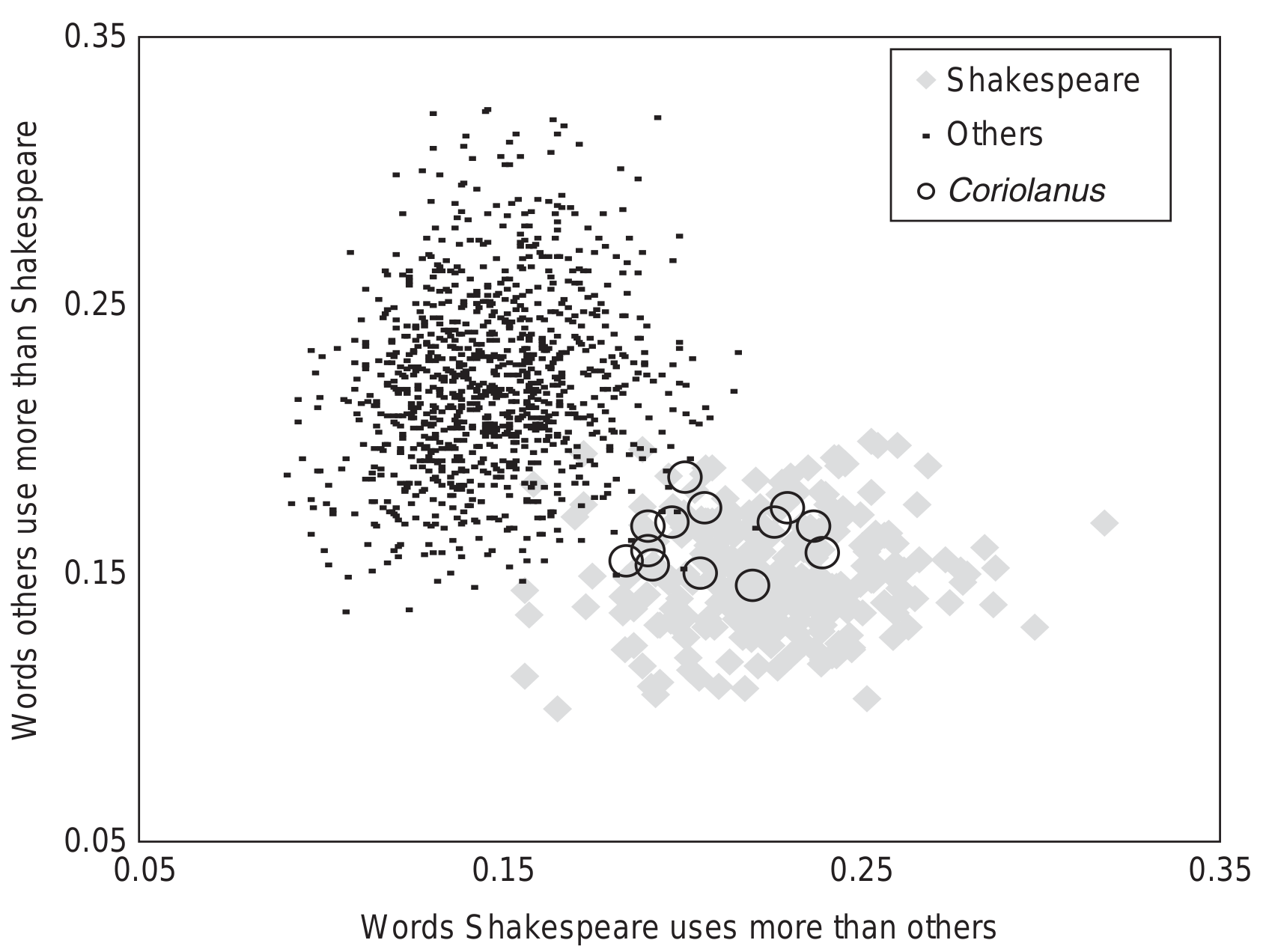
Further uses and discussion of Keyness
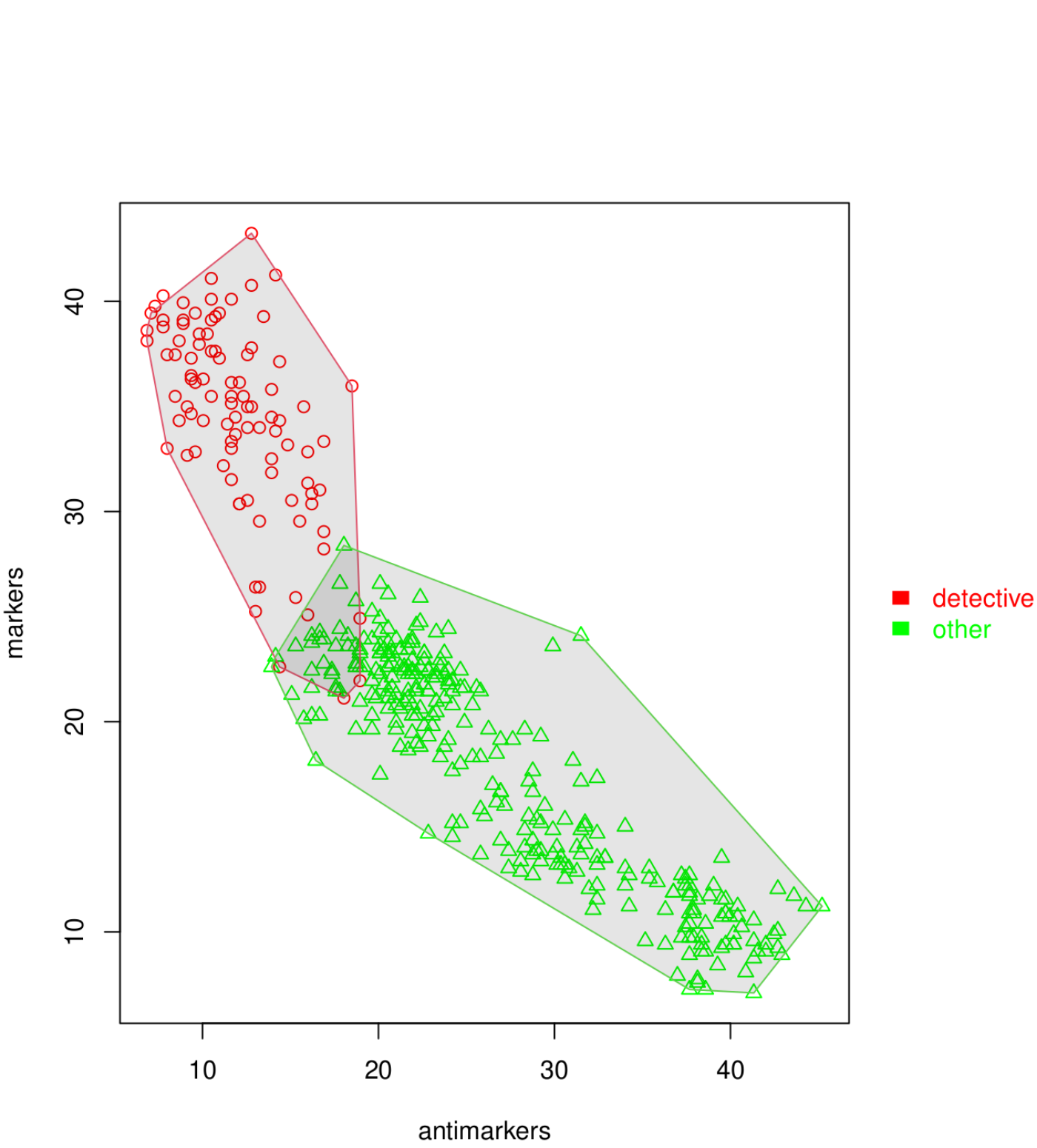
Keyness for gender (Weidman and O’Sullivan 2018)
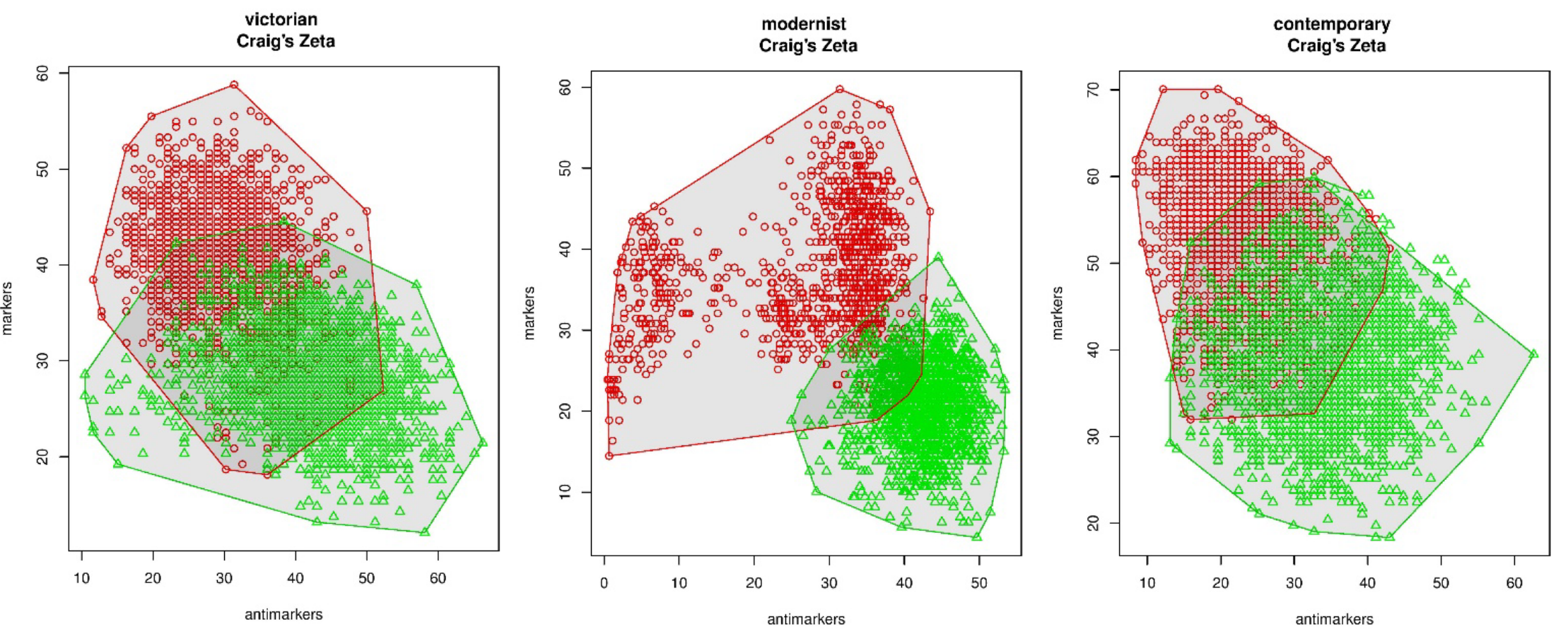
Scatterplot of segments by male and female authors, by percentage of markers and anti-markers, for three literary periods.
Keyness for Genre (Schöch 2018)
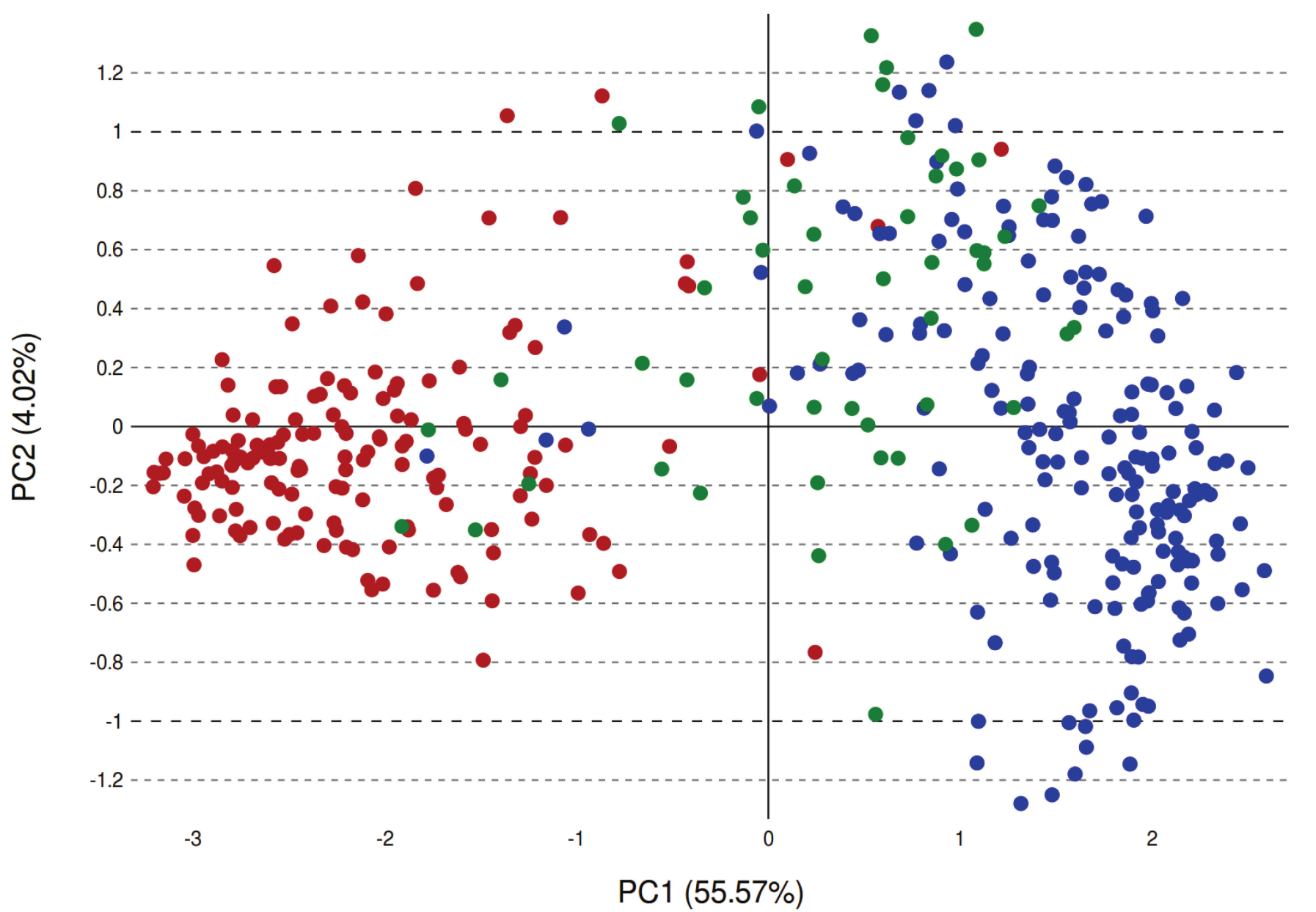
PCA plot using 50 Zeta-based keywords. Comedies in red, tragedies in blue, tragi-comedies in green.
Zeta and Company / Beyond words
- Projects funded by the German Research Foundation (DFG, 2020-2023, 2024-2026)
- Domain of application: popular subgenres of the 20th-century French novel
- Inspirations: John Burrows (Burrows 2007), Jeffrey Lijffijt (Lijffijt et al. 2014), MOTIFS (e.g. Kraif and Tutin 2017), Phraséorom (e.g. Diwersy et al. 2021), dispersion (Gries 2008)
- Fundamental aim: Enable scholars in CLS to make educated choices about what keyness measure to use
- Also: Bridge the gap between Computational Linguistics and Computational Literary Studies
- Activities: modeling, implementing, evaluating and using statistical measures of comparison of two groups of texts.
Quantitative Evaluation:
Classification Task
Data: Corpus of French contemporary fiction

- 320 novels in 8 groups (4 subgenres x 2 decades)
- Published as derived text format – 10.5281/zenodo.7111522
Evaluation Task: Genre Classification
- Downstream classification task: “How reliably can a machine learning classifier, based on words identified using a given measure of distinctiveness, identify the subgenre of a novel when provided only with a short segment of that novel?”
- Basic setup
- 4 classifiers
- Different numbers of keywords (N)
- Textual units are 5000-word segments
- 10-fold-cross validation (90/10 split of segments)
- Baseline: random selection of N words
Results #1
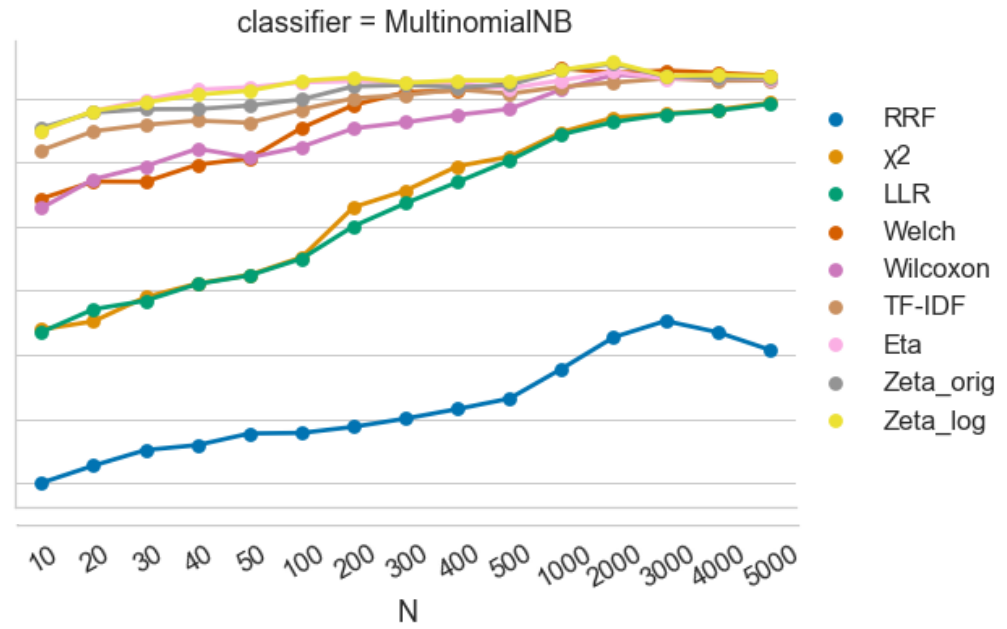
Classification performance on the French corpus (1980s) with four classifiers, depending on the measure of distinctiveness and the setting of 𝑁.
Results #2
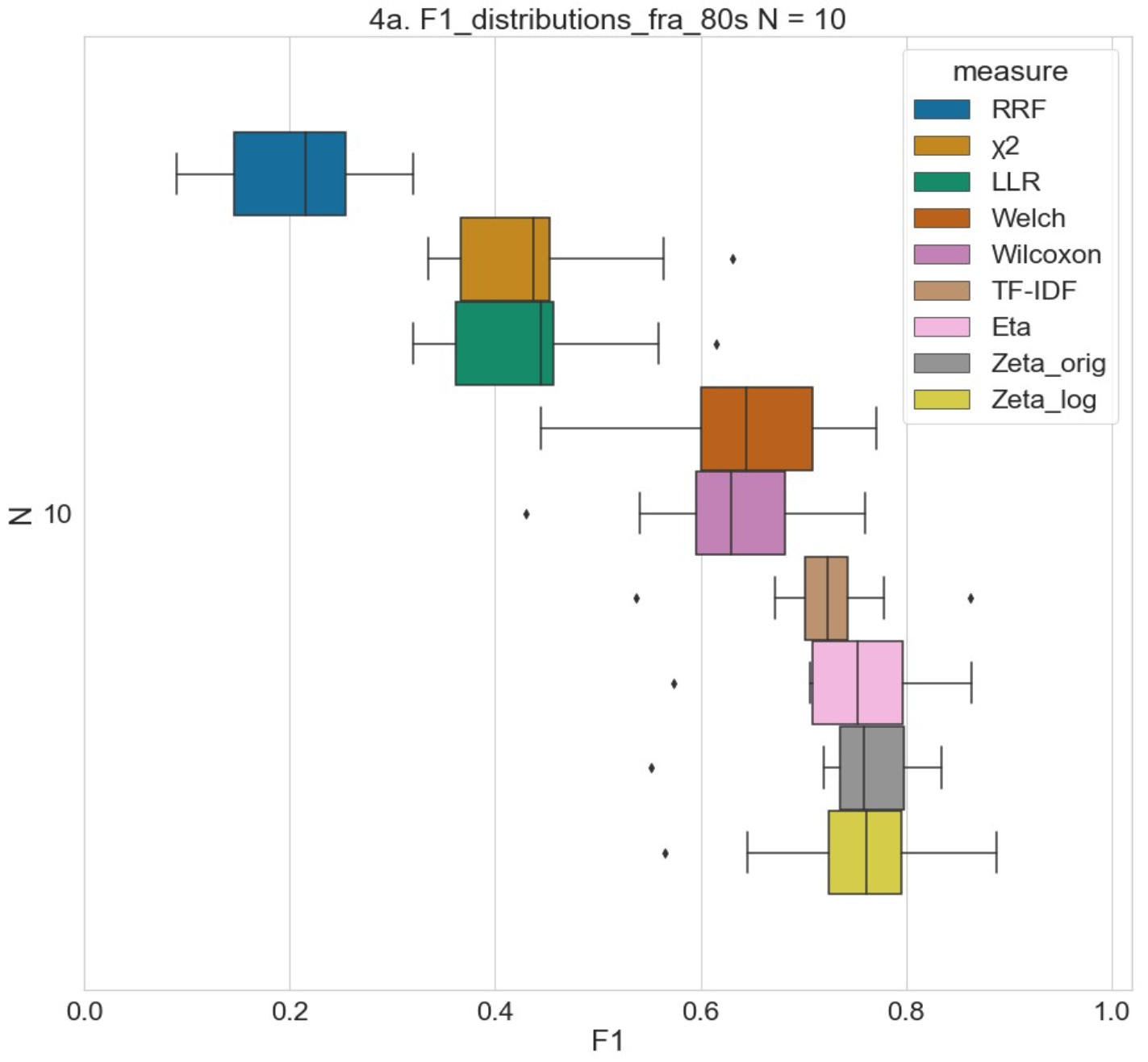
Distribution of classification performance on the 1980s French corpus with N = 10 using Multinomial Naive Bayes
Qualitative Evaluation:
subgenre profiles
Why qualitative evaluation?
- Different kinds of evaluation test different aspects of a measure
- Quantitative evaluation: checks discriminative power
- Qualitative evaluation: focuses on interpretability and aboutness
Our approach: match keywords with sugenre profiles
- Establish ‘subgenre profiles’
- Based on scholarly literature
- Systematically describe subgenres:
setting, characters, themes, narrative form, language, etc.
- Create lists of keywords for each subgenre
- For three measures: Log-likelihood ratio, Zeta, Welch
- Annotate the lists wrt to relevance to subgenre profiles
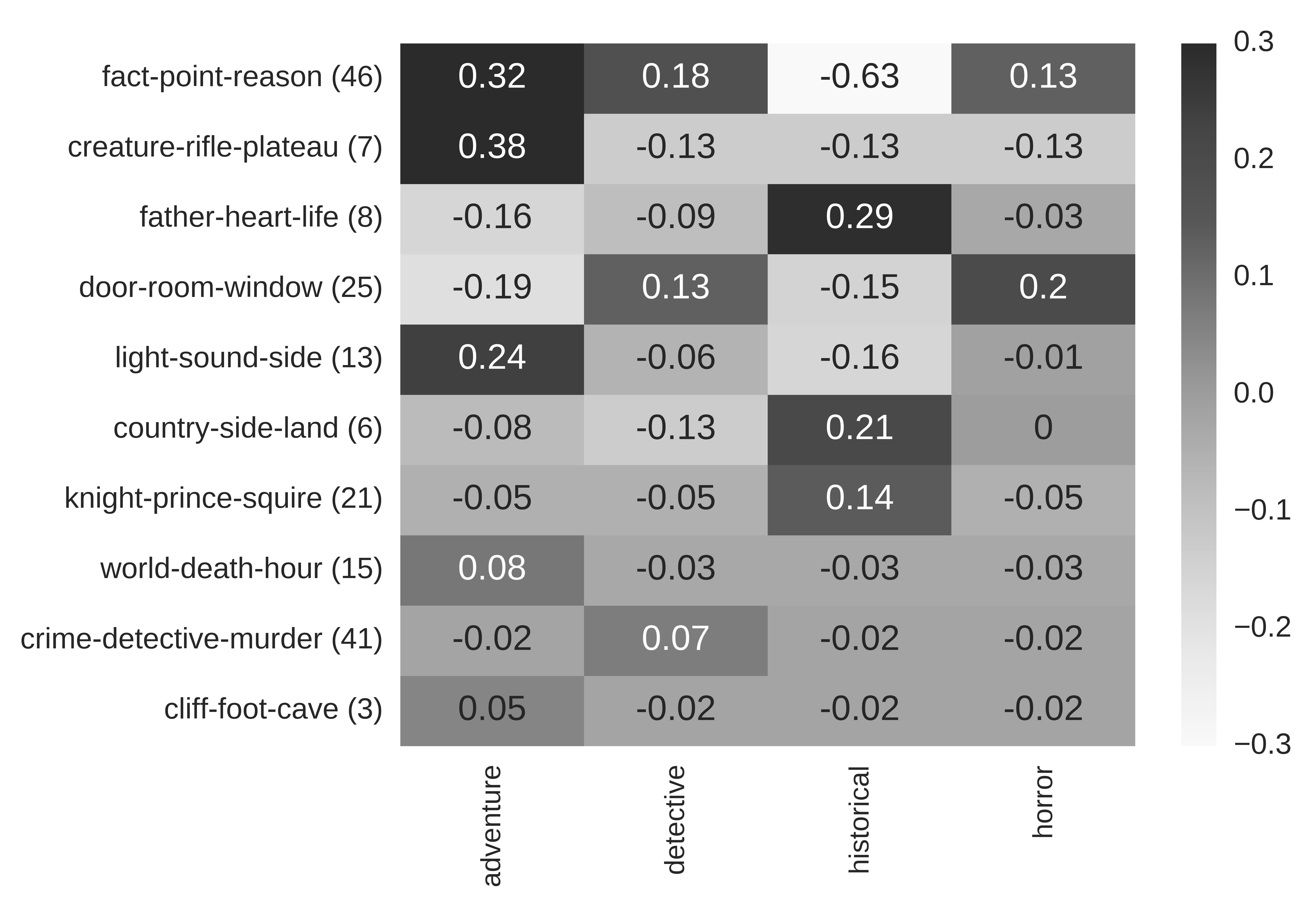
Example: ‘setting’ in science fiction
| Science fiction | Zeta | LLR | Welch |
|---|---|---|---|
| Space / Setting: Solitary settings are typical, e.g. space, desert or the arctic. Vast and imaginative array of settings, e.g. space, alternate universes, hallucinatory landscapes, the moon, Mars. | planet, space, surface, universe, ground, star, zone, outside, spatial | planet, space, universe | planet, ground, space, surface, outside, universe, zone |
| 9/50 | 3/50 | 7/50 |
Results: Interpretability of measures
- Interannotator agreement (Cohen’s kappa): κ=0.33 (low!)
- General interpretability (left)
- high: Zeta and Welch
- low: Log-likelihood ratio
- Matches of keywords with subgenre profile categories (right)
- Highly variable, somewhat inconclusive
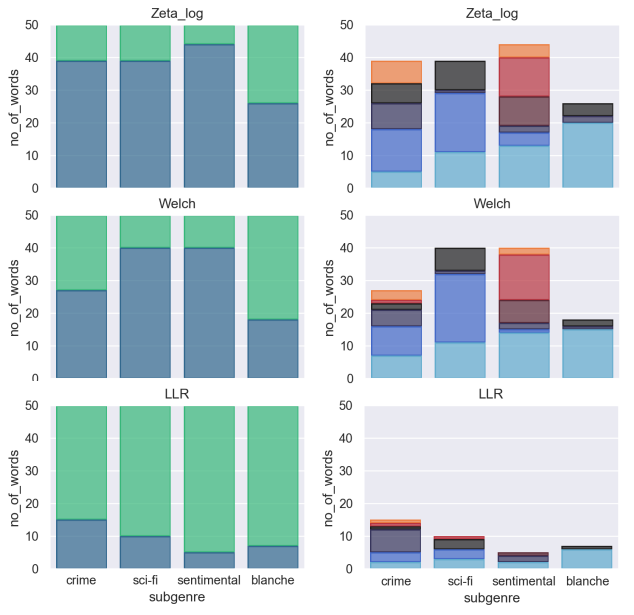
Conclusion: Findings and Outloook
What have we found out so far?
- Definition
- Keyness should not be defined as ‘unusual frequency’; aspects like discriminatory power, salience or aboutness are important.
- A match between a certain understanding of keyness and a specific measure can be established using a suitable method of evaluation.
- Evaluation
- Dispersion-based keyness measures show best performance in a subgenre classification task, especially when the number of features is small
- Dispersion and distribution-based measures tend to select medium-frequency words that are highly-interpretable and fare well in a qualitative evaluation
- Zeta
- Zeta is a fully competitive keyness measure, and often preferable to Log-likelihood ratio in the context of CLS
What are the next steps?
- Perform further experiments, using synthetic texts and test tokens with pre-determined frequency- and/or dispersion-based contrasts
- Consider additional measures:
- measure based on DPnofreq (Gries 2021),
- LRC / effect size (Evert 2022);
- Fisher’s exact test (Lebart and Salem 1994)
- Move on to more complex features: multi-word expressions and semantic features (Beyond Words, 2024-2026)
- Find a strategy for how to handle a multi-dimensional approach to keyness (multiple meanings, multiple measures), e.g. along the lines proposed in (Gries 2019)
Thank you for your kind attention!
References
Bonus slides
Measures with references (Du, Dudar, and Schöch 2022)
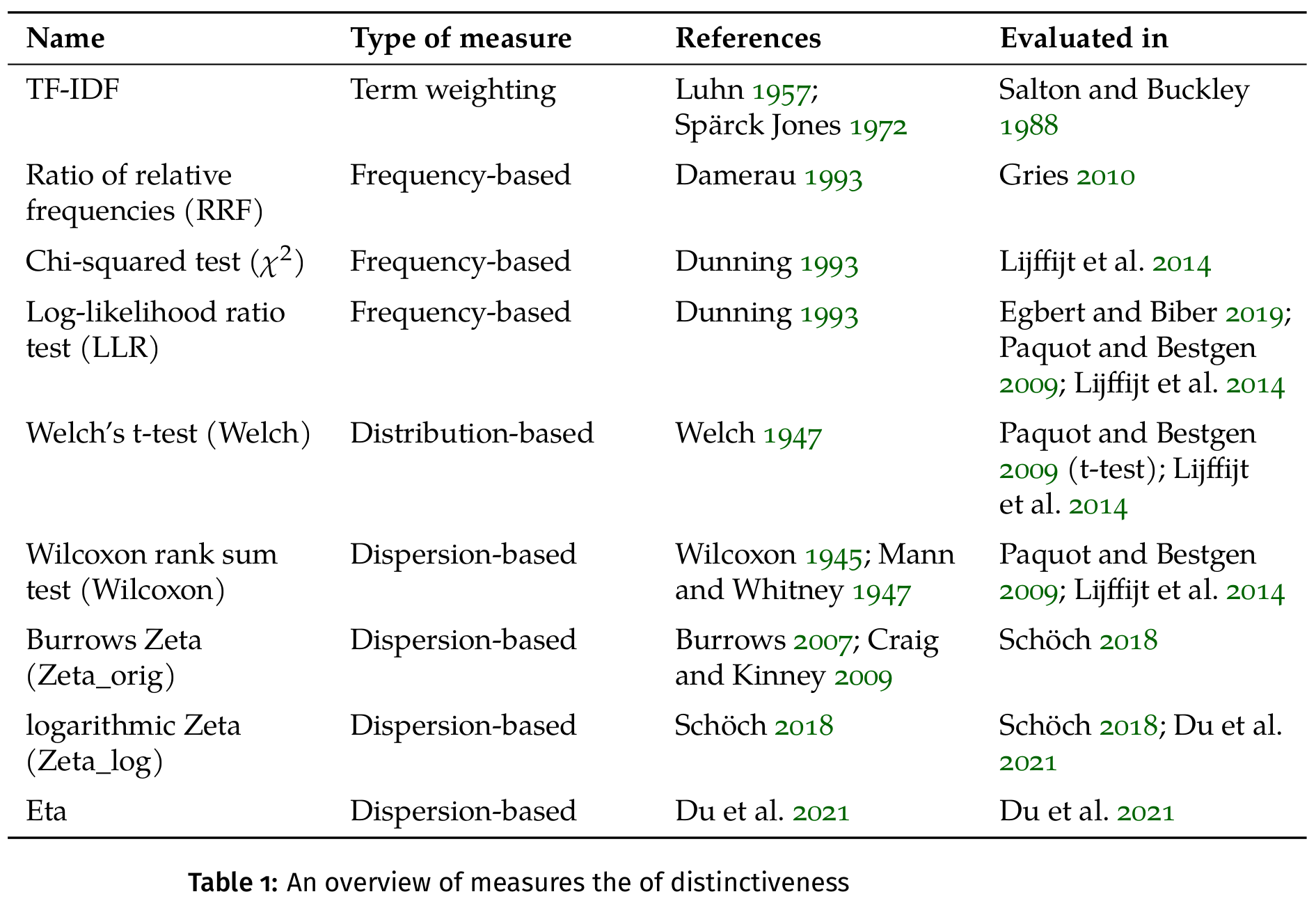
All corpora (Du, Dudar, and Schöch 2022)
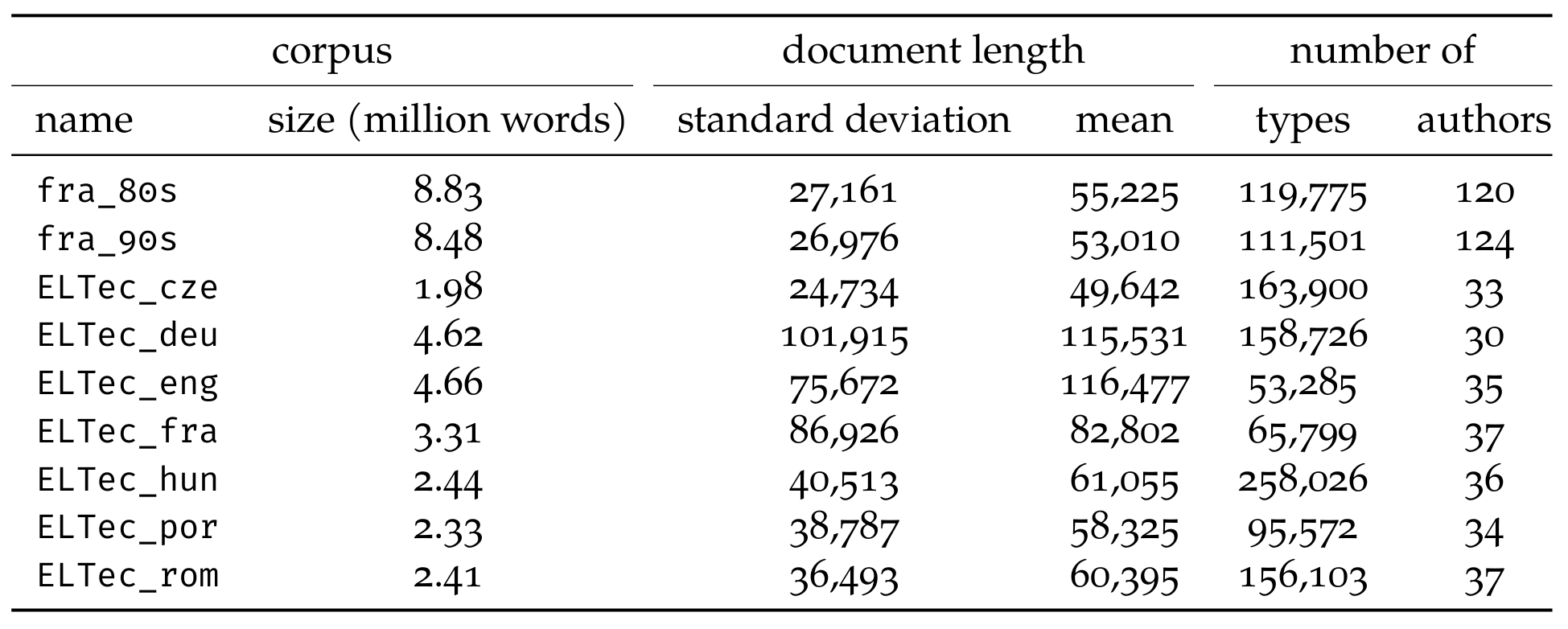
Correlation between measures (Du, Dudar, and Schöch 2022)
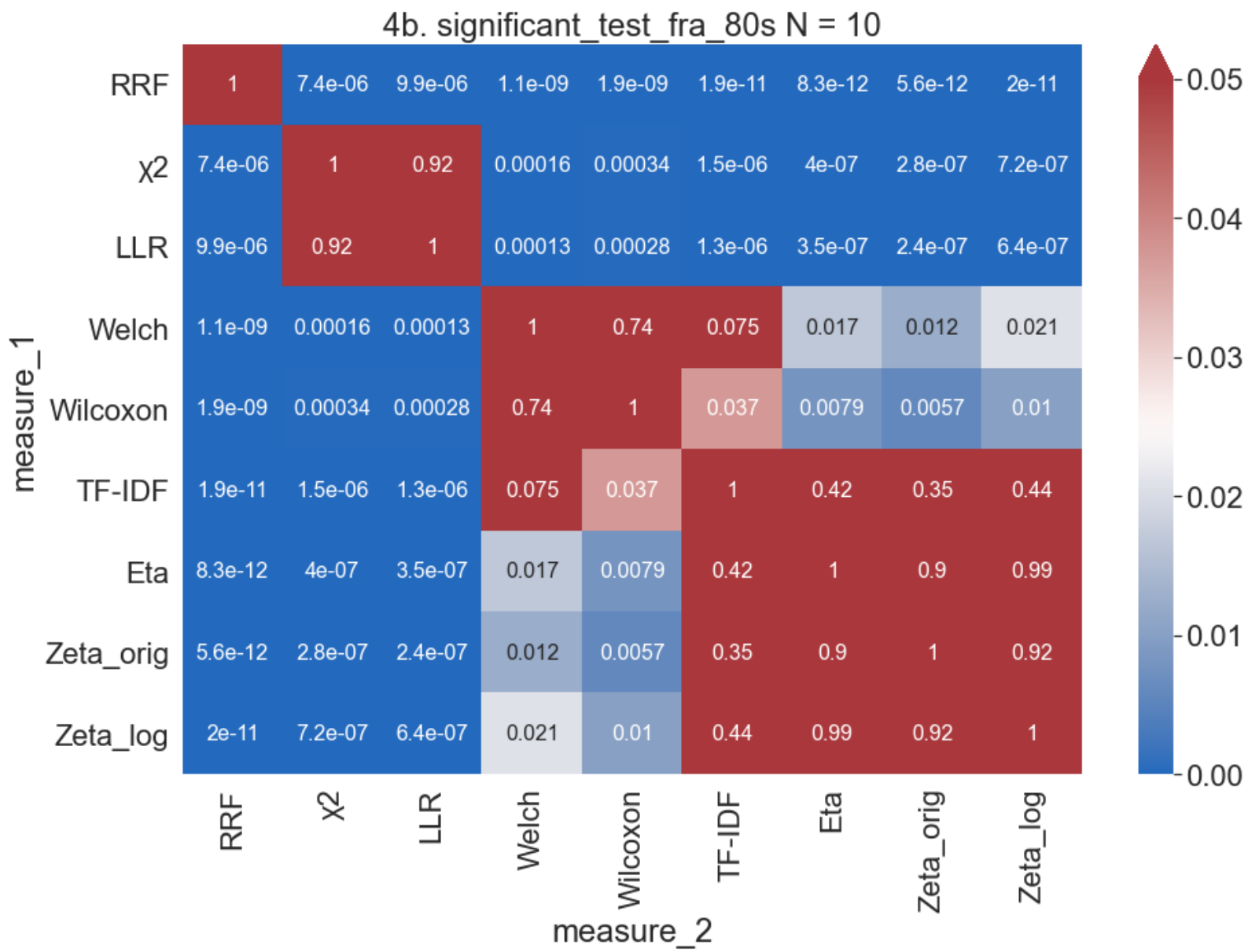
Keyness in stylo: genre (A.C. Doyle)