Bigger Smarter Data
Extracting, Modeling and Linking Data for Literary History
23 May 2024
Thanks
![]()
![]()
Seung-eun Lee of Korea University / Department of Korean Language and Literature / Humanities Utmost Sharing System, and Byungjun Kim, KAIST, on behalf of KADH (Korean Association for Digital Humanities).

The Ministry for Research, Education and Culture of Rhineland-Palatinate, Germany, for funding this research (Mining and Modeling Text, 2019-2023)
![]()
Thanks to all the project contributors: Maria Hinzmann, Matthias Bremm, Tinghui Duan, Anne Klee, Johanna Konstanciak, Julia Röttgermann and many others.
Third Way: Bigger Smarter Data
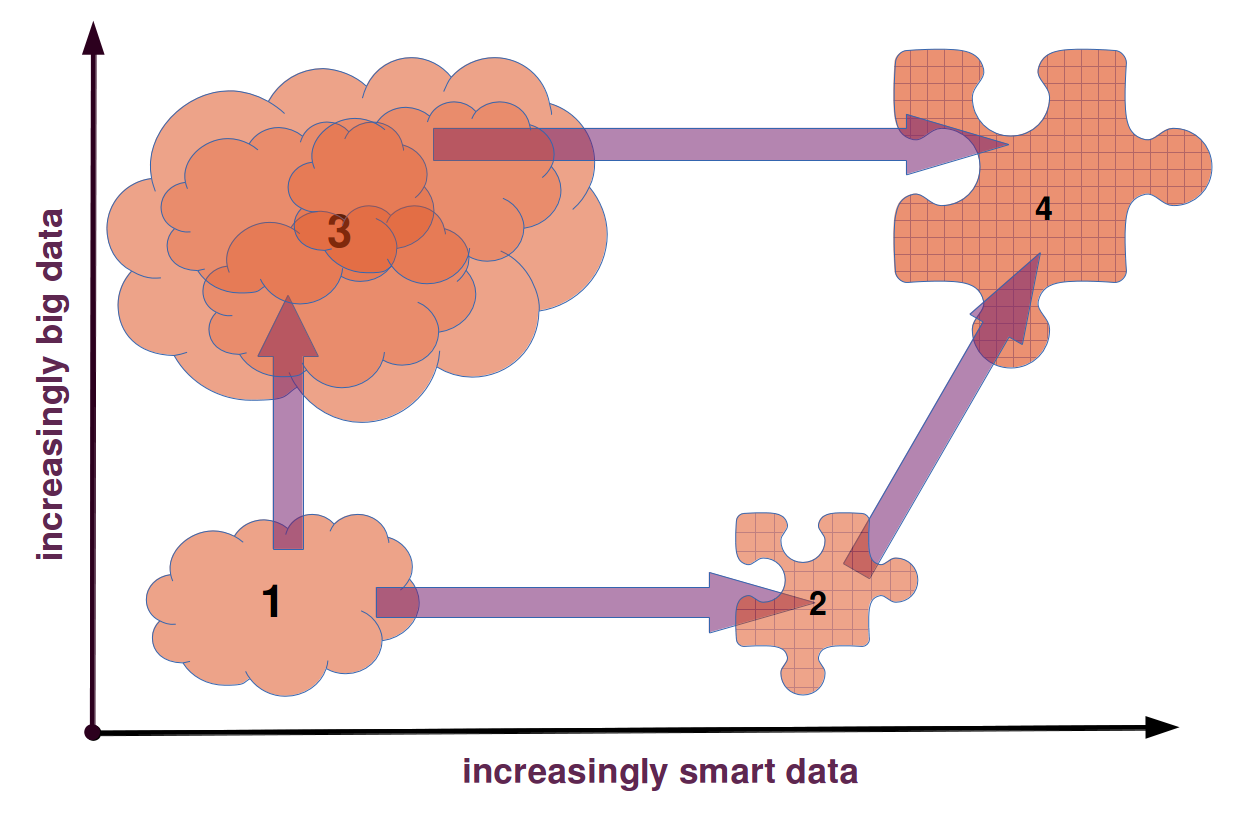
Background: What is Linked Open Data?
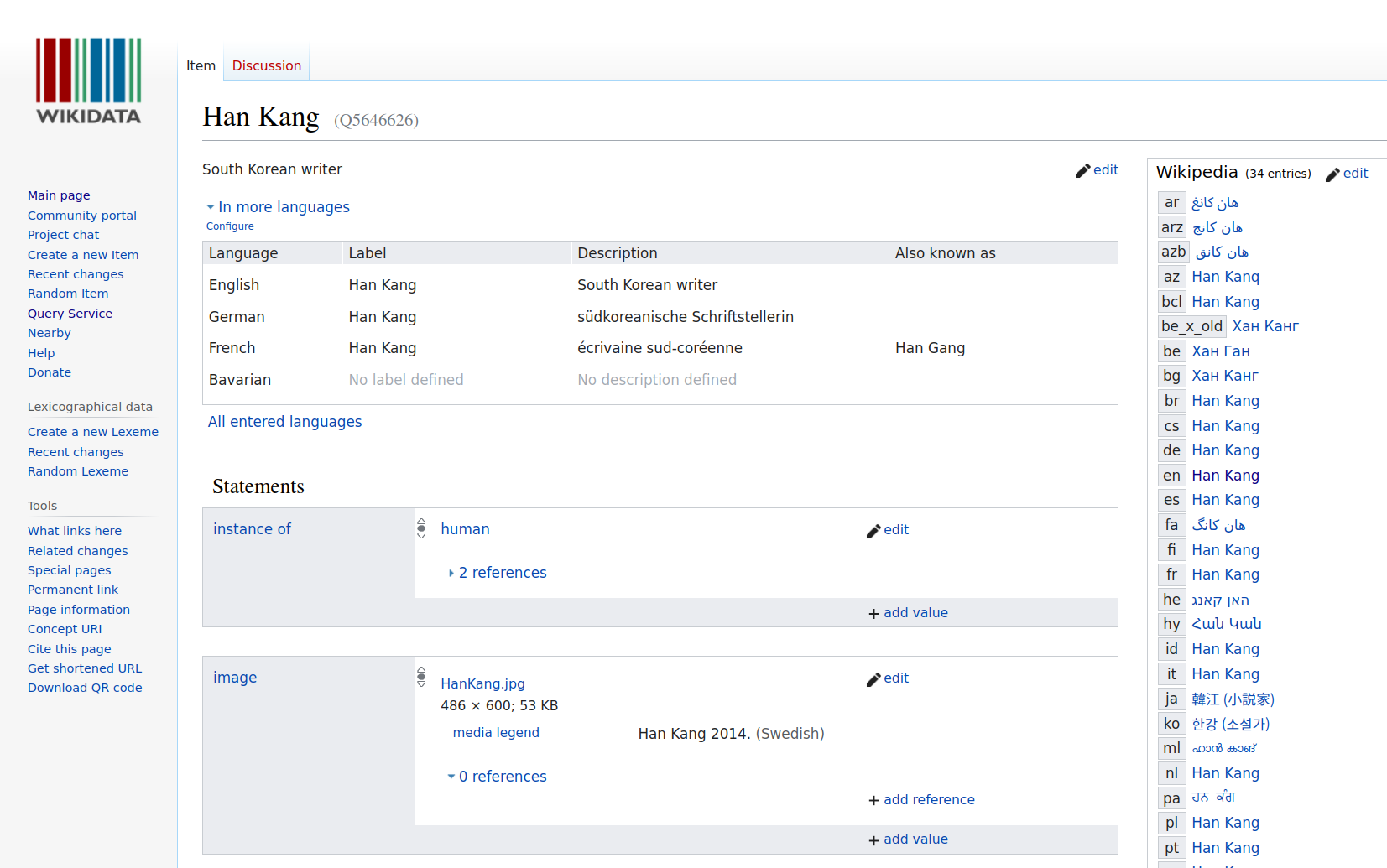

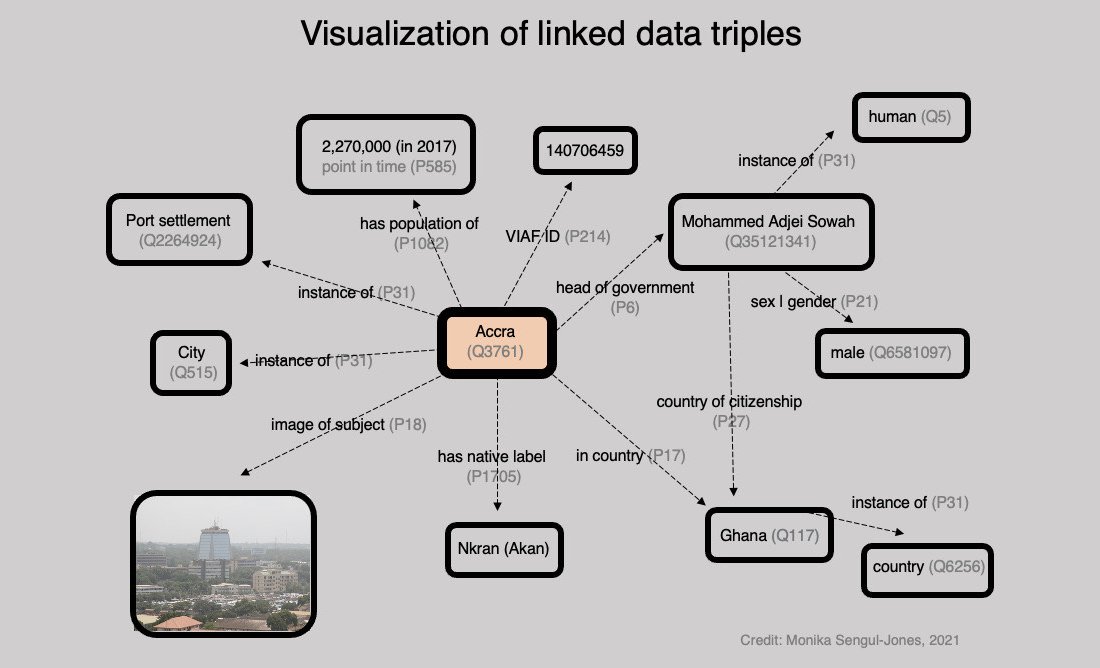
Linked Open Data: Multilingualism
The project ‘Mining and Modeling Text’
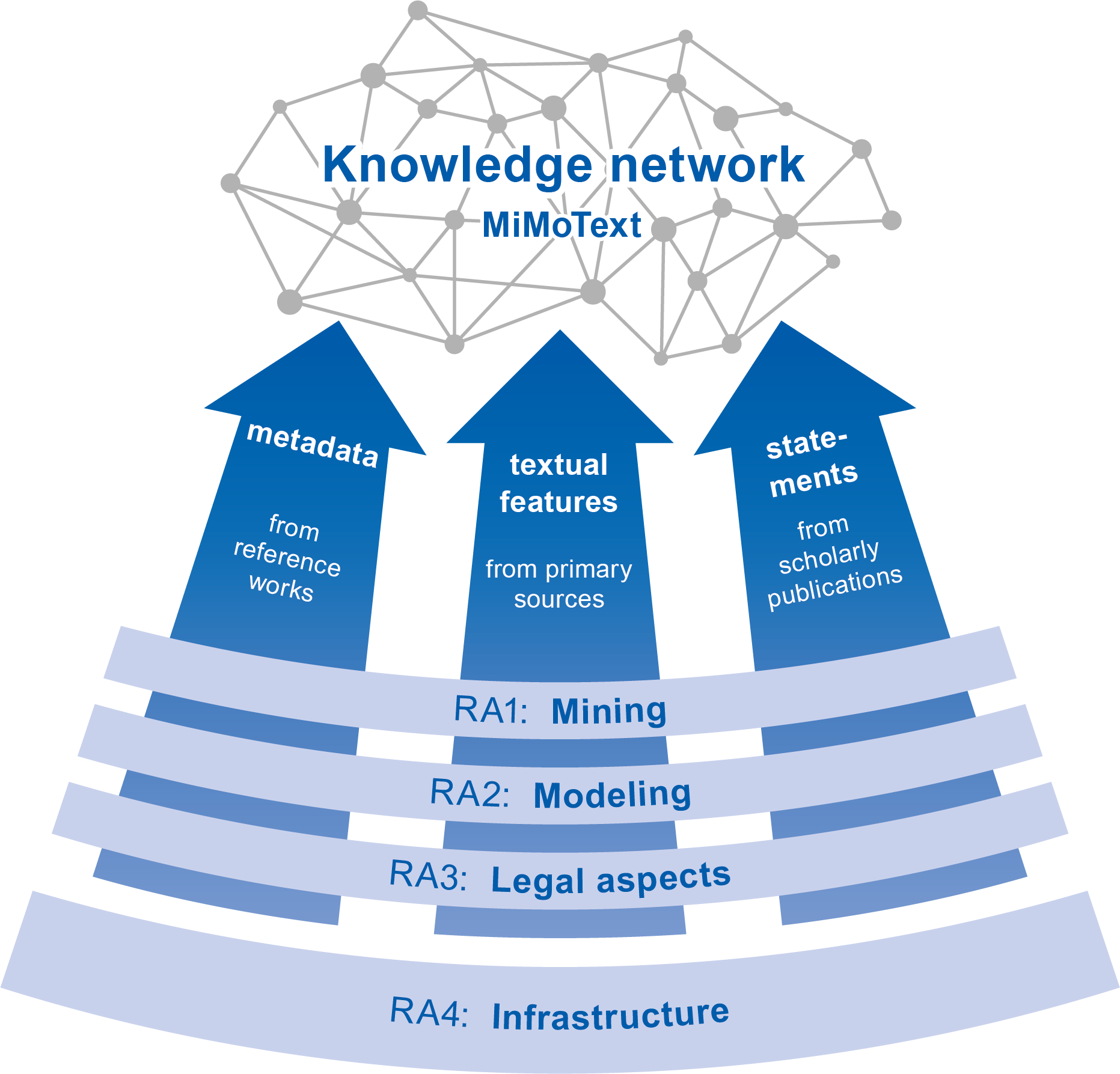
Pillar 1: Bibliographie du genre romanesque français

Pillar 2: primary literature (novels)
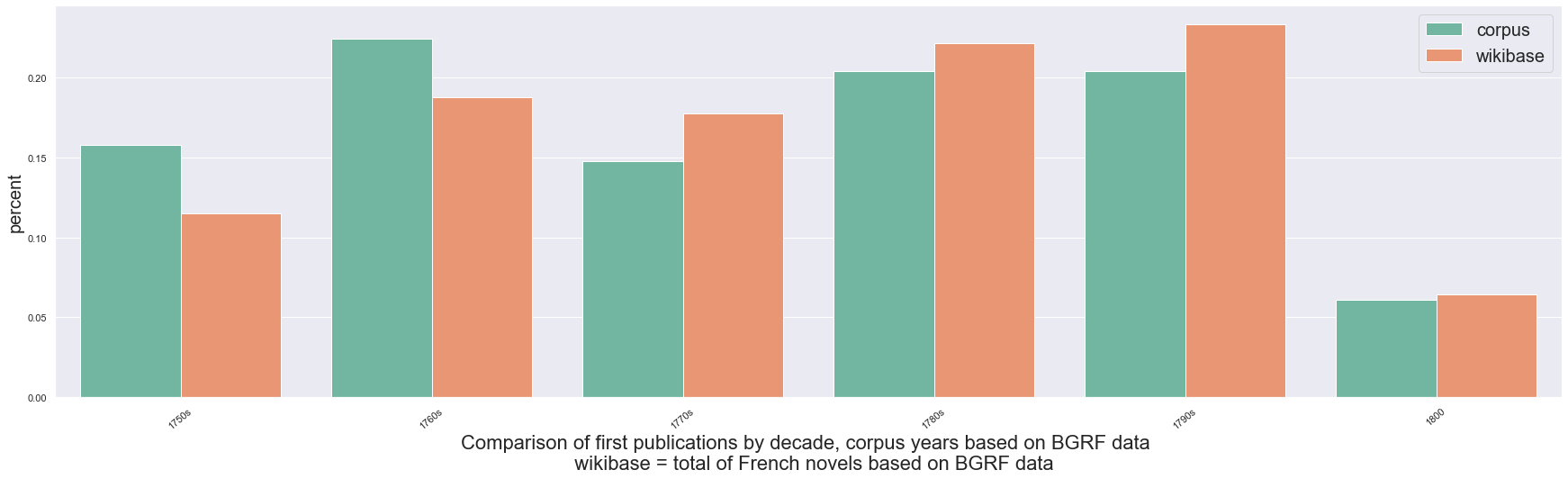
- Corpus of 200 French novels (1750-1800)
- Encoding: in XML-TEI, with metadata, according to ELTeC schema
- Methods of analysis: Topic modeling, NER, stylometry, etc.
Pillar 3: Scholarly Literature
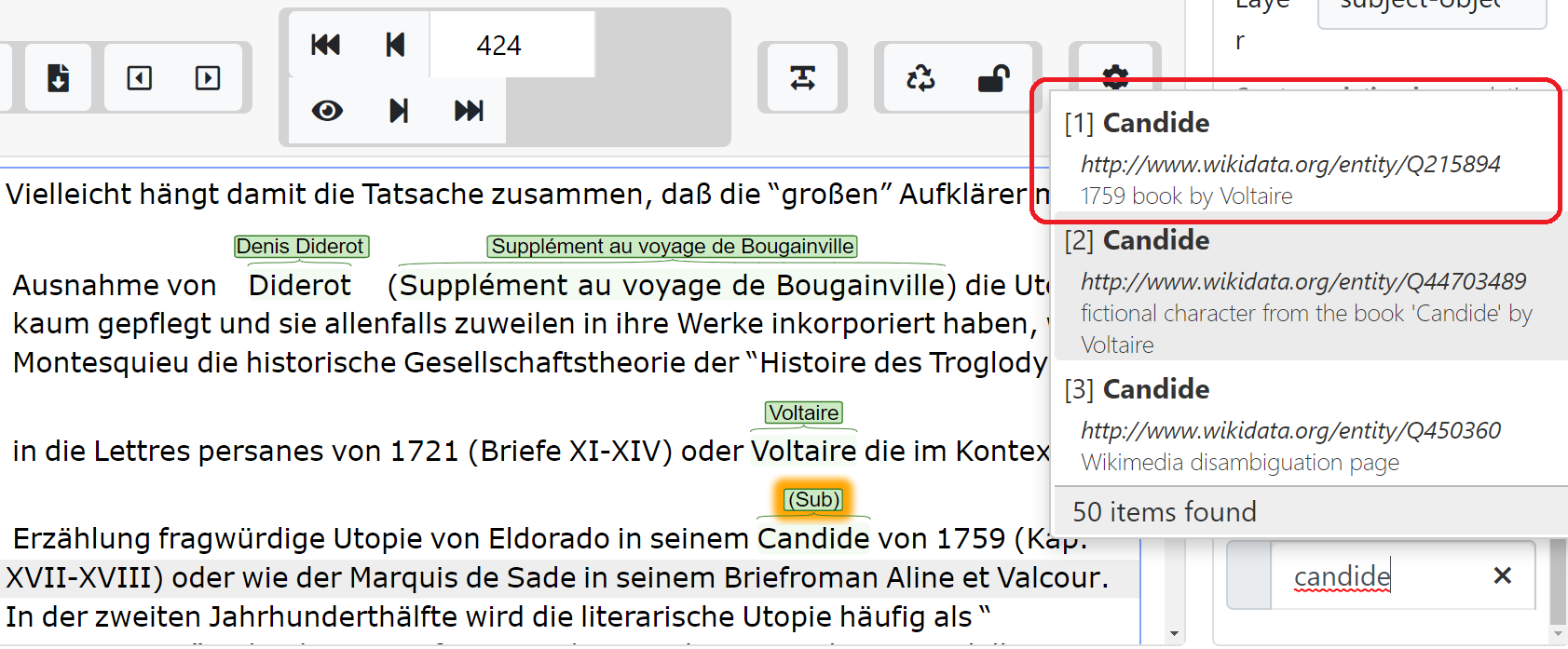
- Annotation guidelines => Manual annotations (using INCEpTION)
- Linking of INCEpTION with MiMoTextBase and Wikidata => disambiguation
- Creation of statements about authors and works (genres, themes, etc.)
- Machine Learning based on the annotated training data
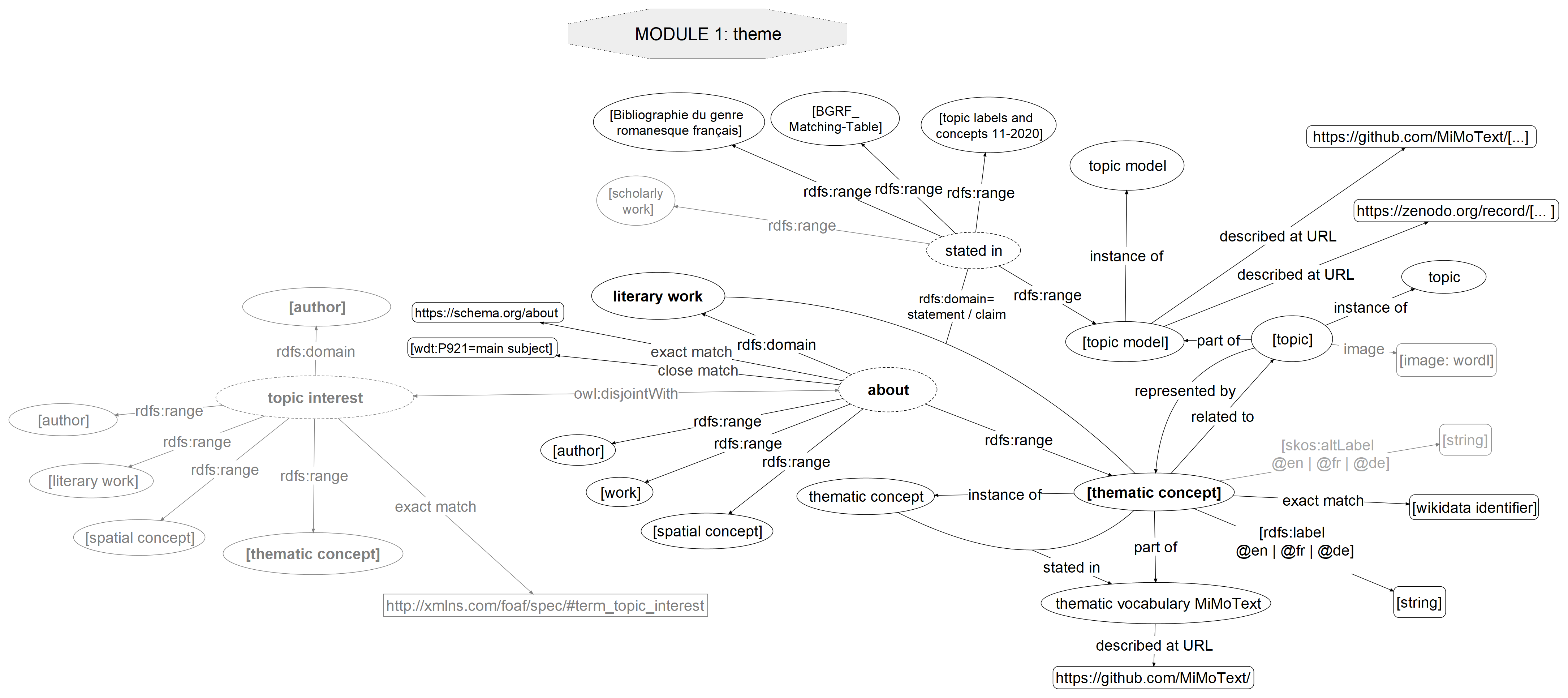
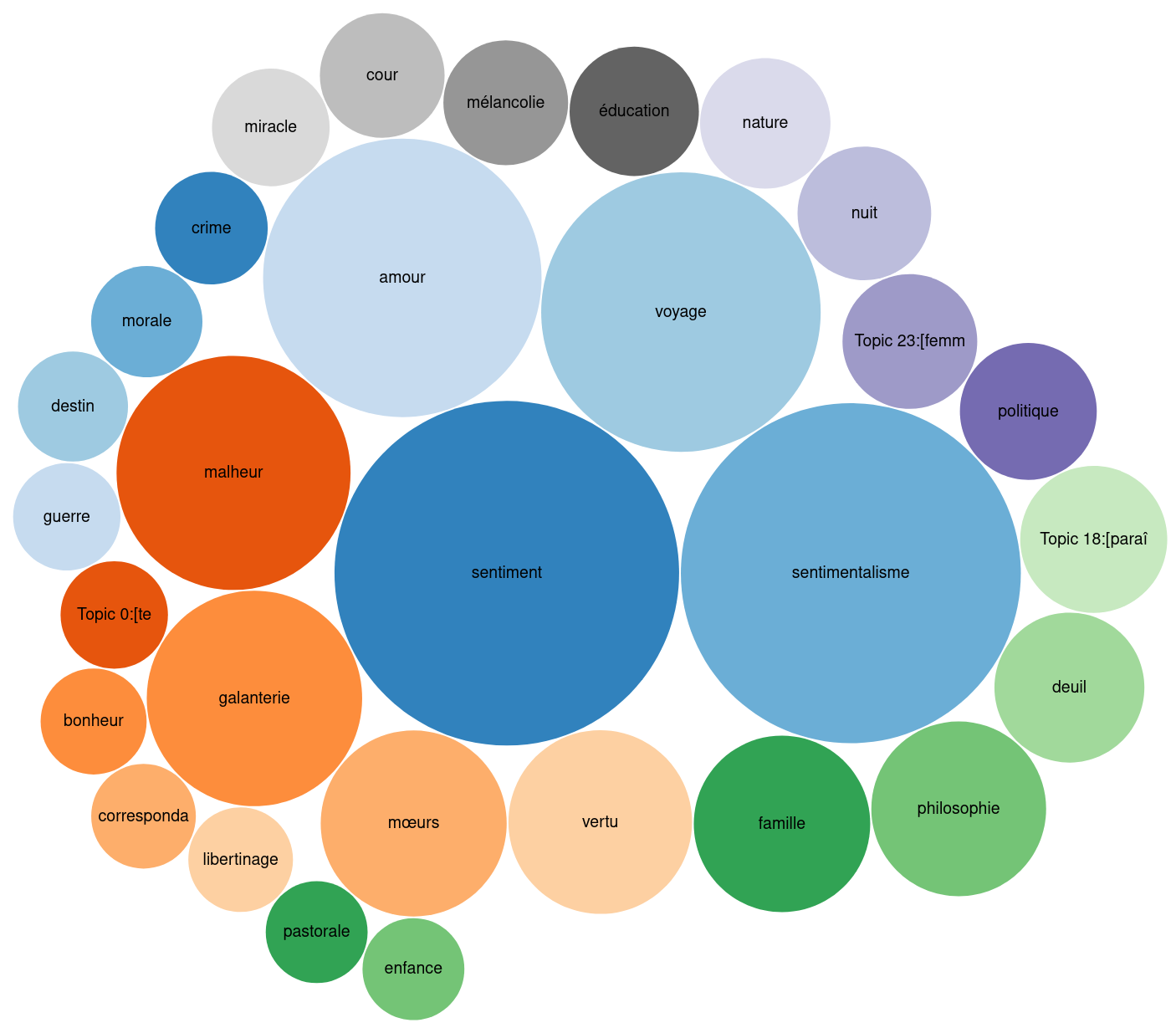
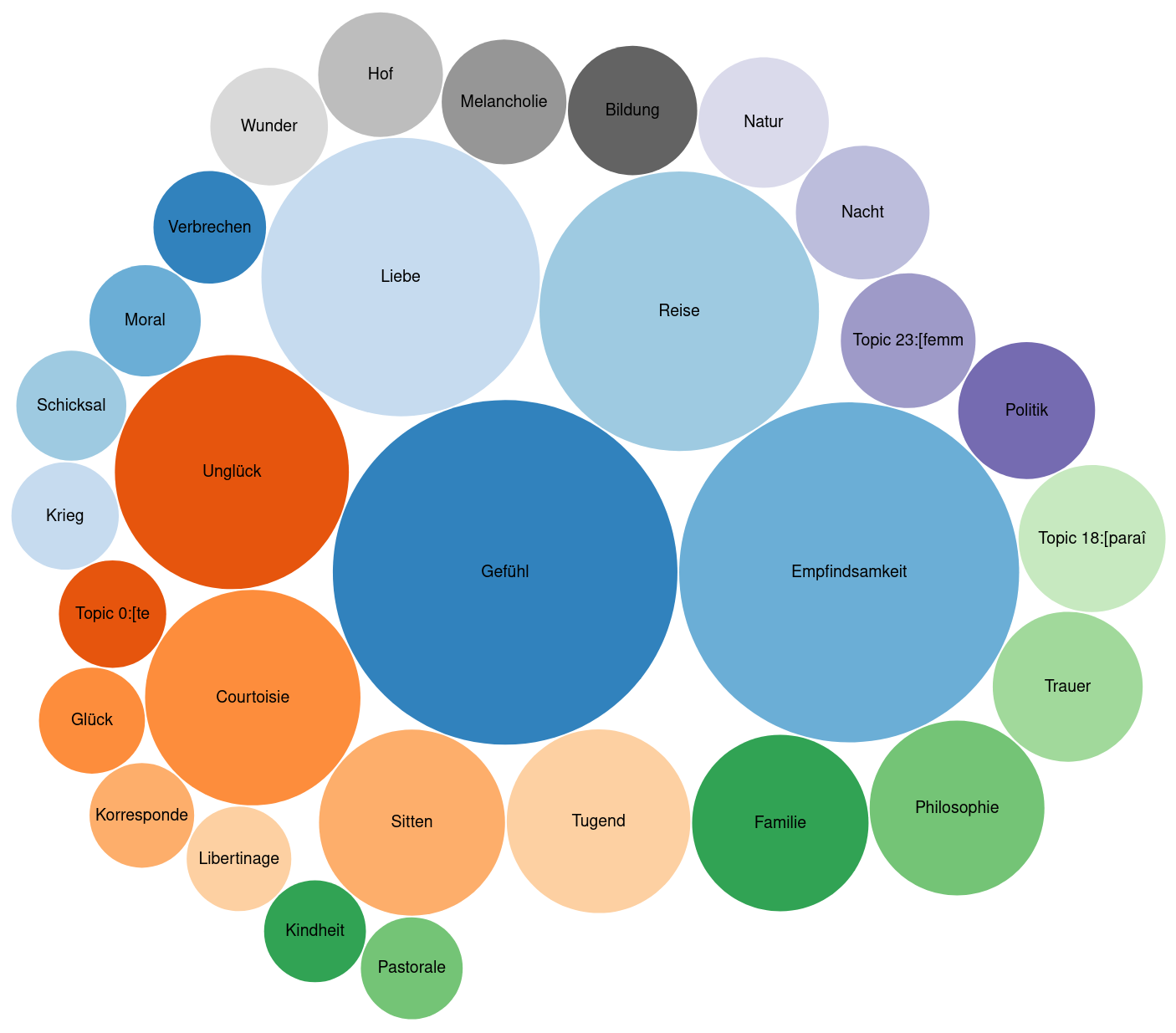
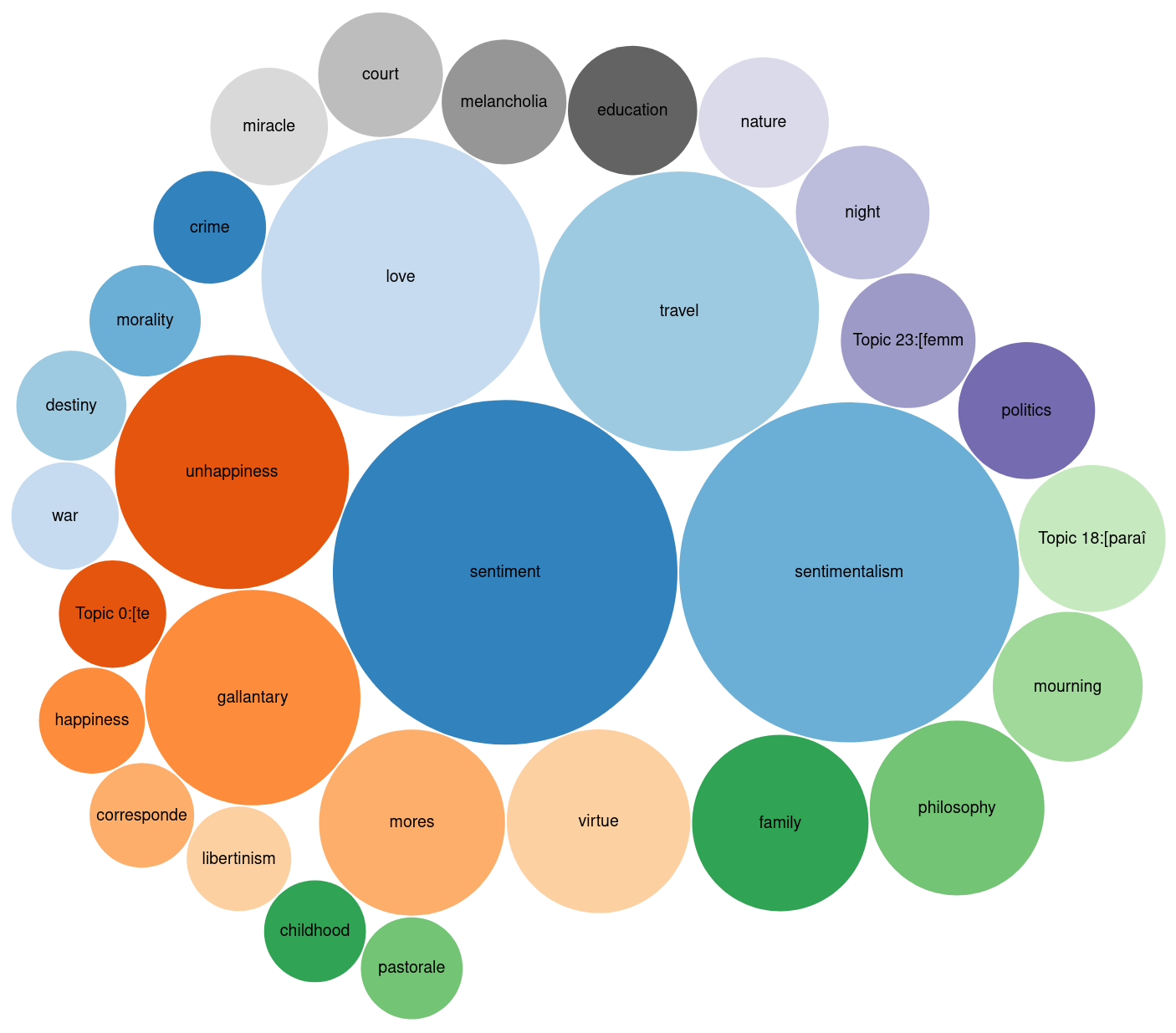
Example: The module on themes
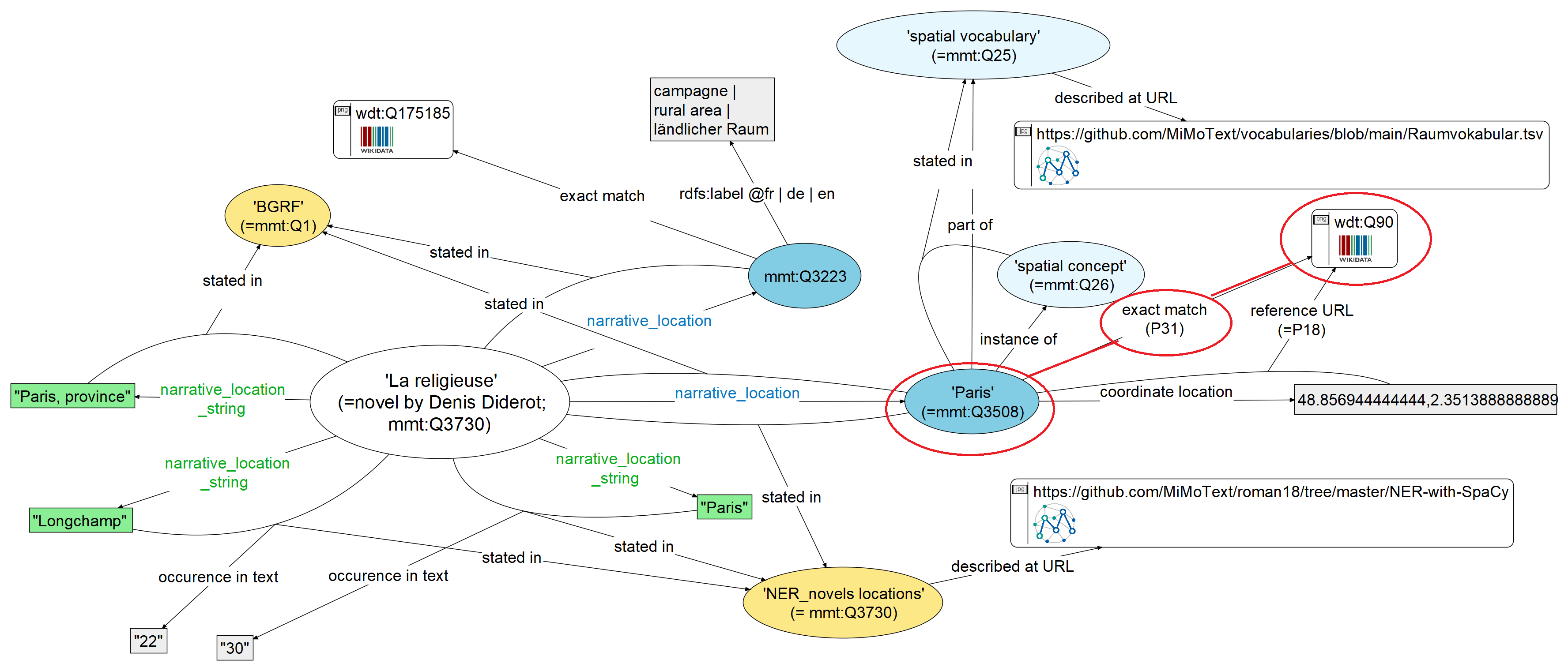
Example: The module on narrative location
Meta-Statements

Linking with Wikidata for ‘federated queries’
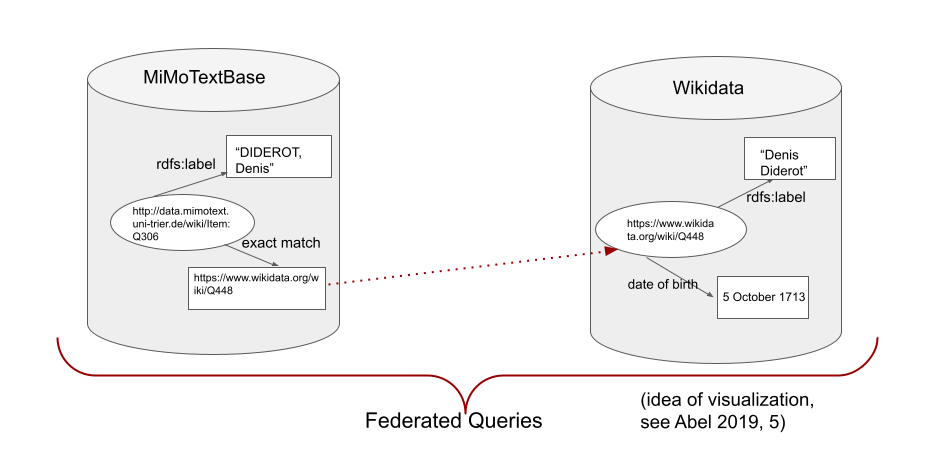
The MiMoTextBase
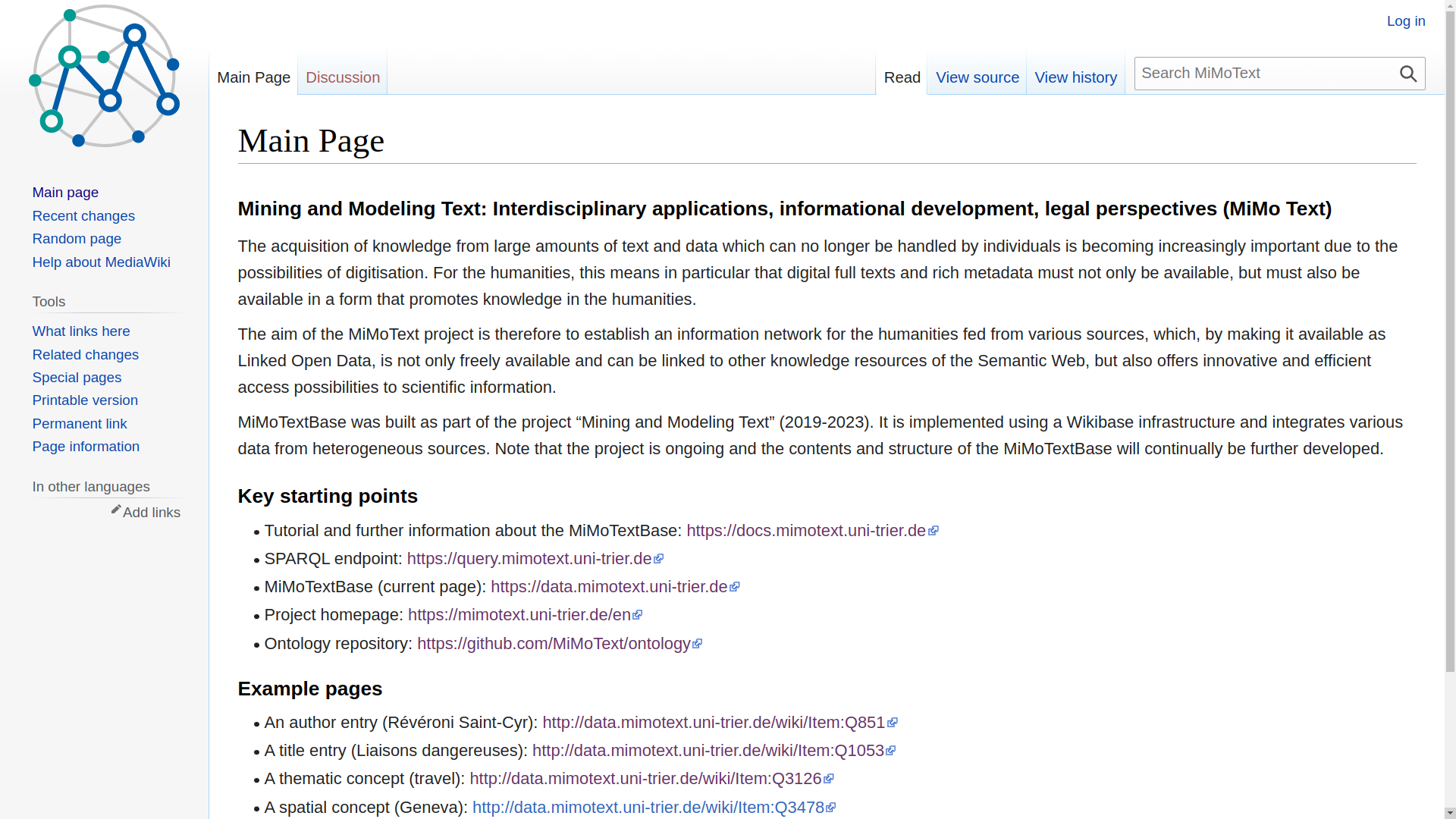
SPARQL endpoint
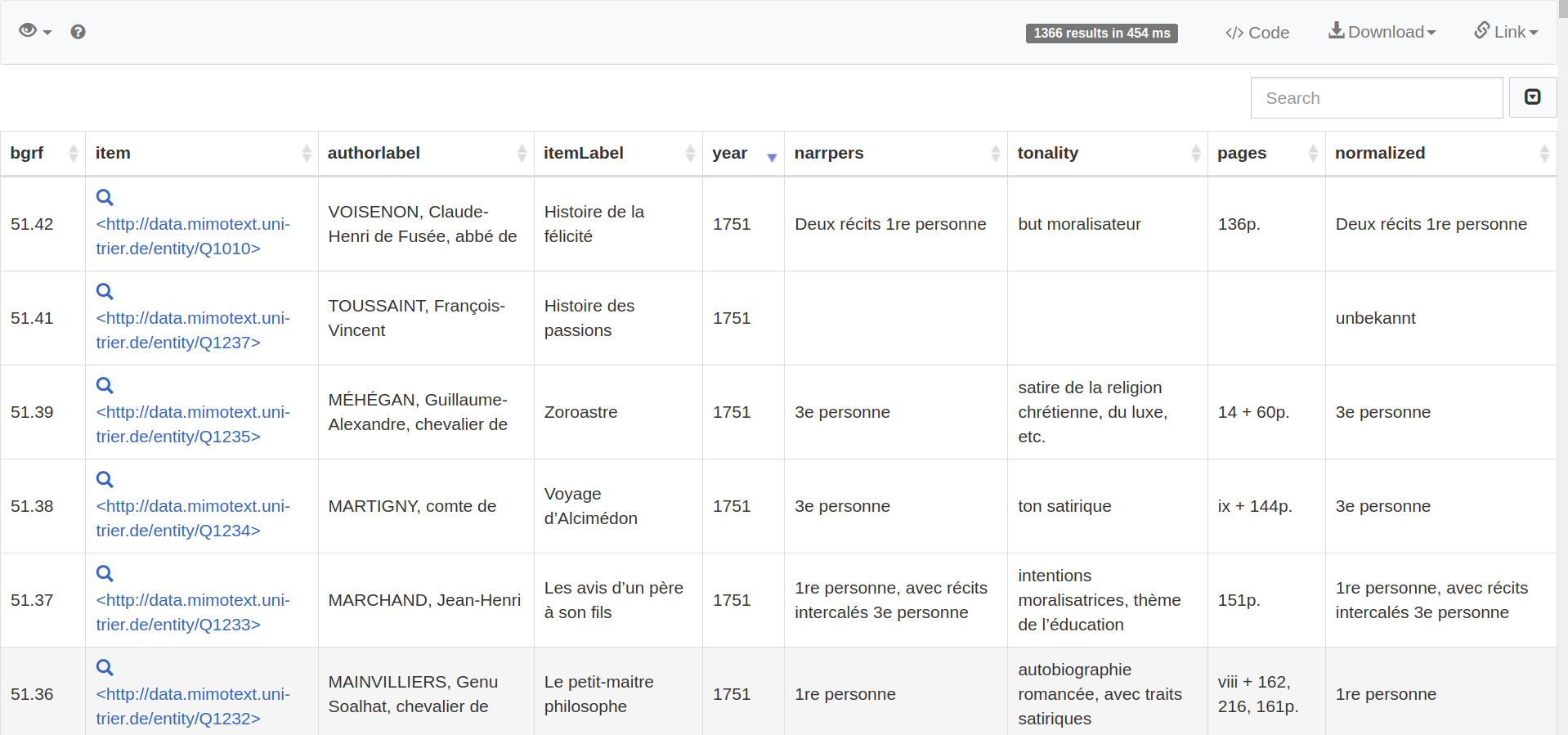
MiMoText Base: Query for themes in novels
References
Martin, Angus, Vivienne G. Mylne, and Richard Frautschi. 1977. Bibliographie du genre romanesque français, 1751-1800. Mandell.
Röttgermann, Julia. 2024. “The Collection of Eighteenth-Century French Novels 1751-1800.” Journal of Open Humanities Data 10 (1): 31. https://doi.org/10.5334/johd.201.
Schöch, Christof. 2013. “Big? Smart? Clean? Messy? Data in the Digital Humanities.” Journal of Digital Humanities 2 (3): 1–19. https://journalofdigitalhumanities.org/2-3/big-smart-clean-messy-data-in-the-humanities/.
Schöch, Christof, Maria Hinzmann, Julia Röttgermann, Katharina Dietz, and Anne Klee. 2022. “Smart Modelling for Literary History.” International Journal of Humanities and Arts Computing 16 (1): 78–93. https://doi.org/10.3366/ijhac.2022.0278.
![]()