Grundlagen großer Sprachmodelle
Von word2vec über BERT bis zu GPTs
07 Nov 2025
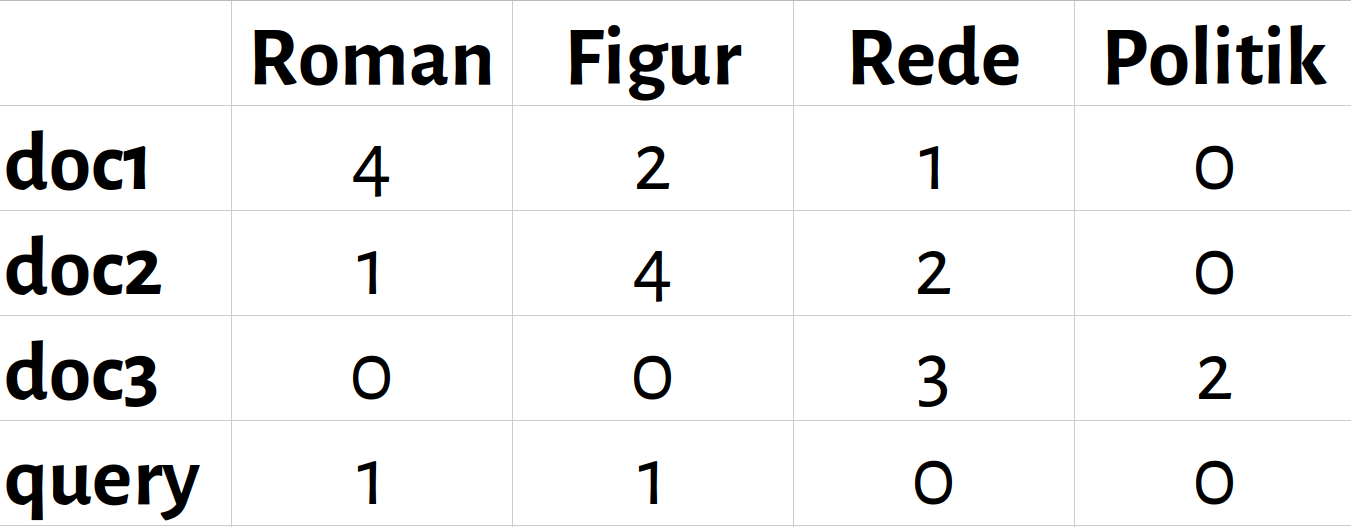
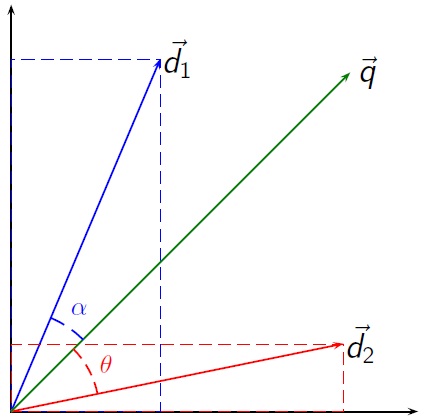
Vektorraum-Modell im Information Retrieval
- Jedes Dokument ist durch die Häufigkeit seiner Keywords beschrieben
- Ein Query besteht ebenfalls aus Keywords
- Räumliche Nähe im Vektorraum = Ähnlichkeit von Query und Dokument
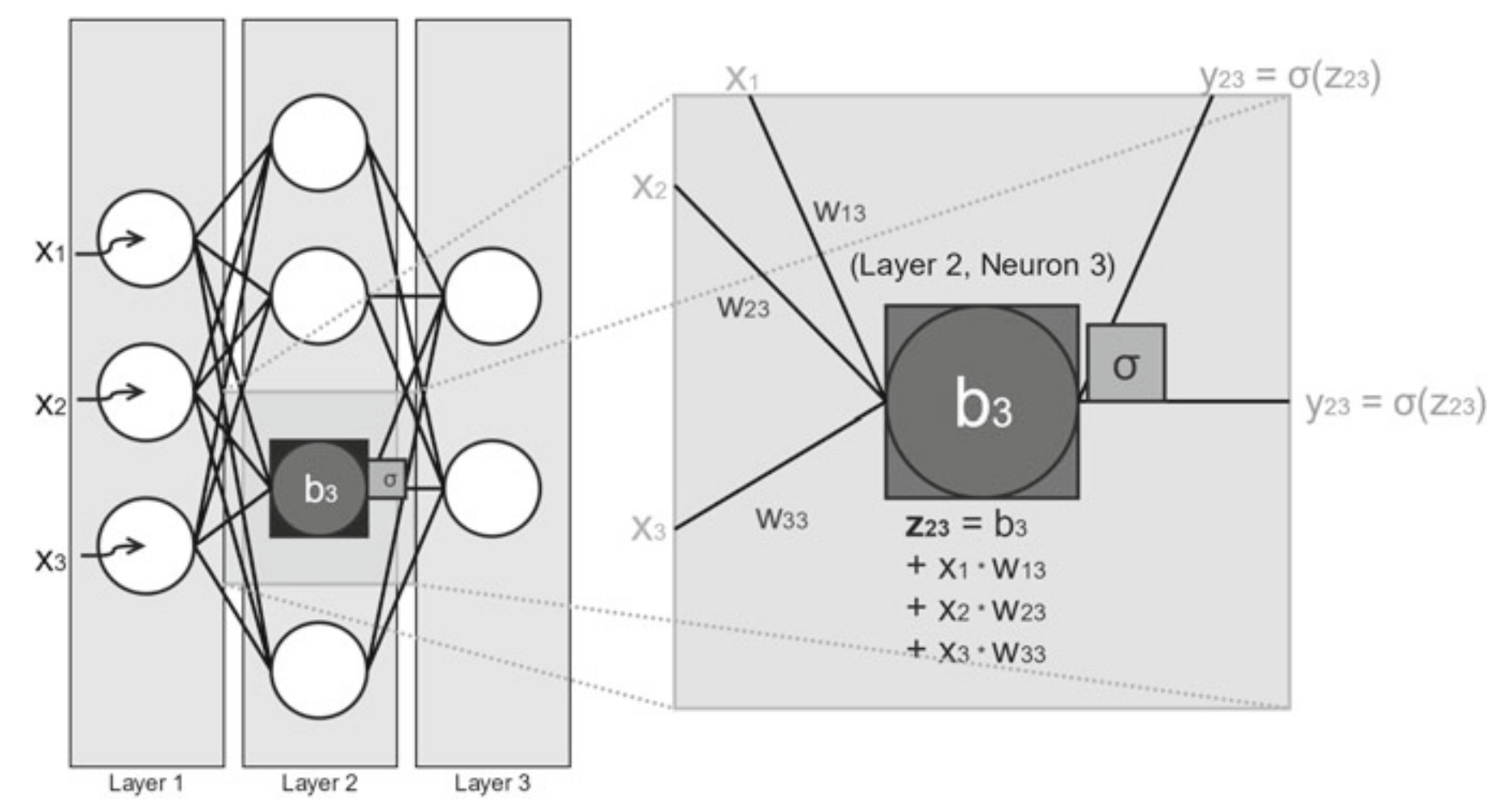
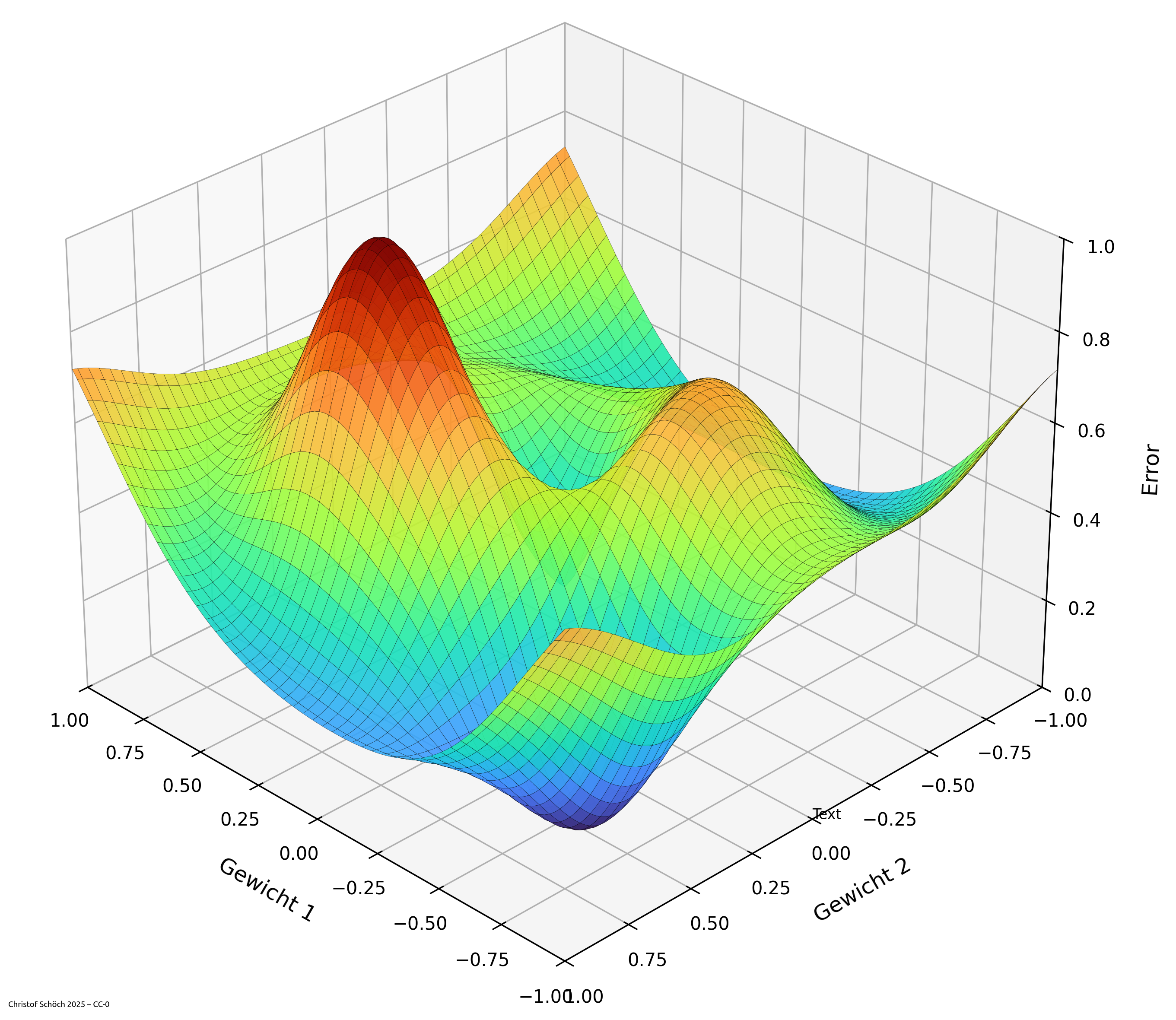
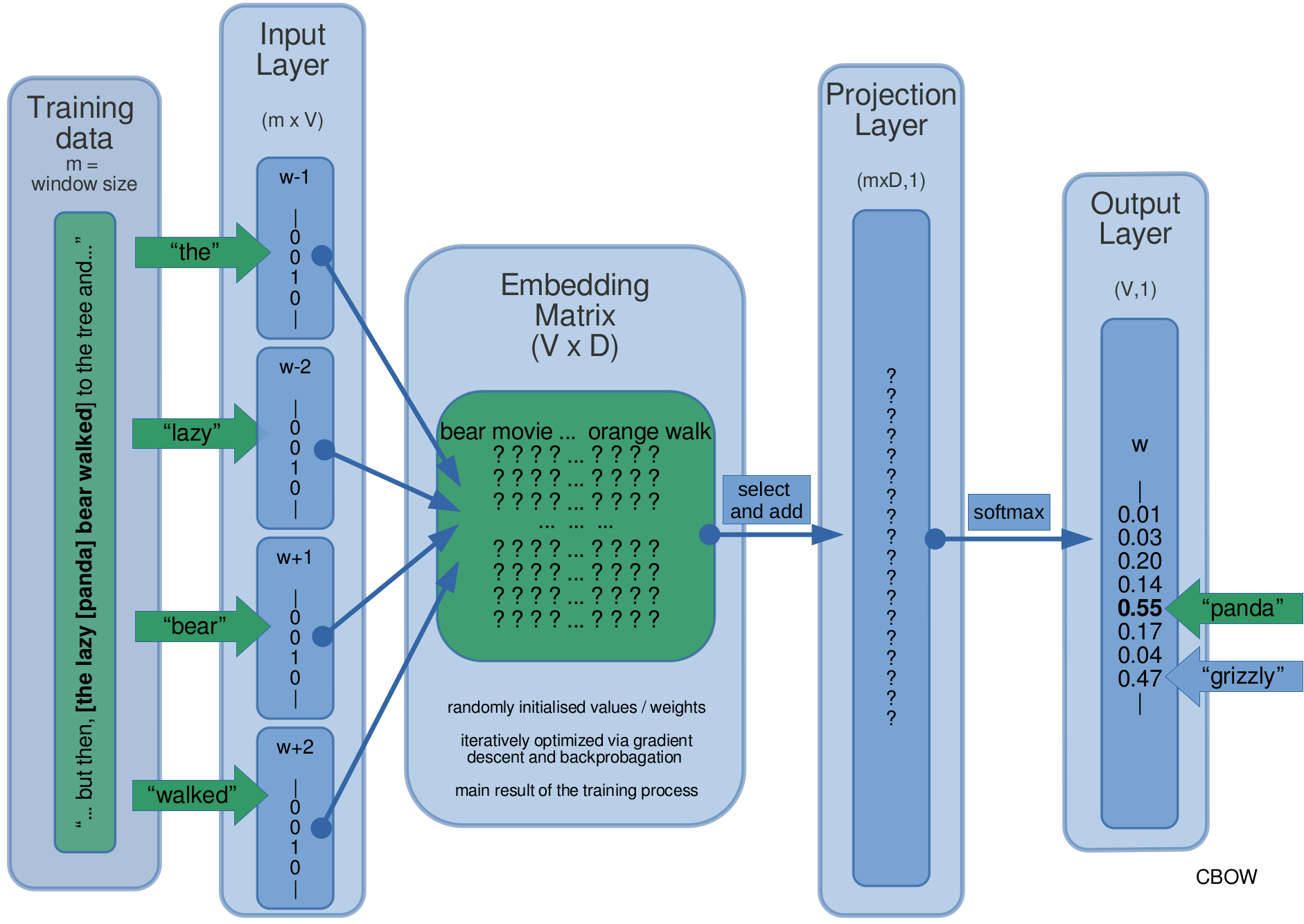
Lernen = Gewichte optimieren (Gradient Descent)
- Neuronales Netz: Gewichte zufällig initialisieren
- Klassifikationsaufgabe bearbeiten
- Rückmeldung zur Abweichung zwischen Antwort und Lösung
- Gewichte werden minimal und zielführend angepasst
- Mechanismus: “gradient descent”
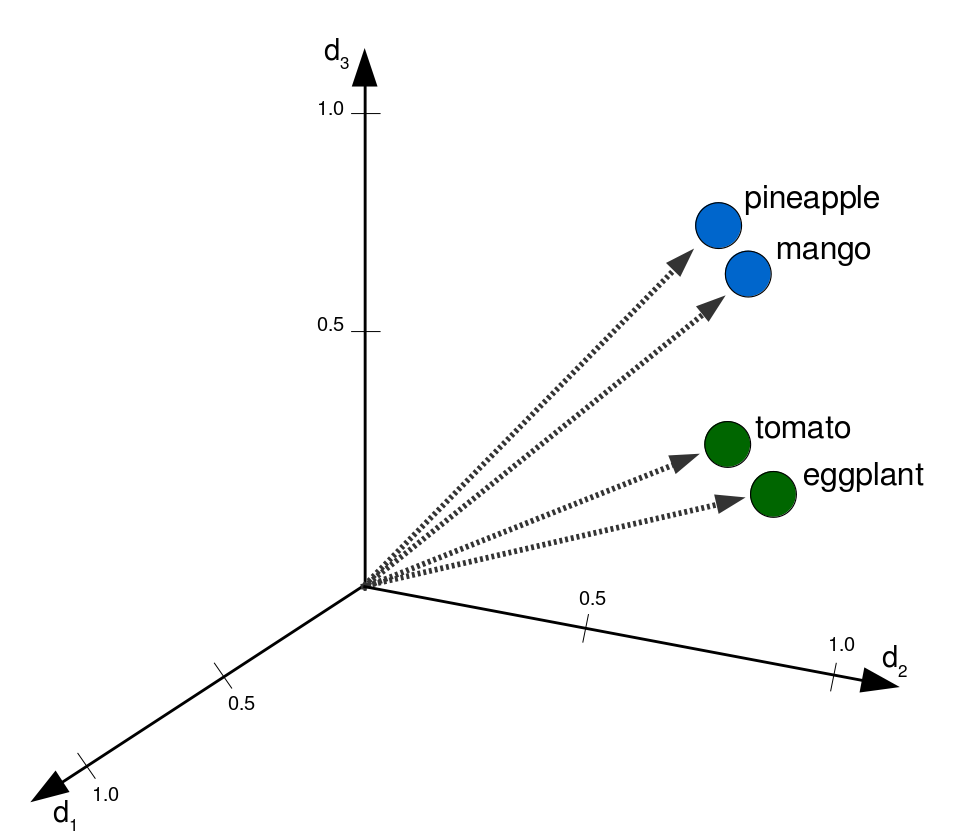
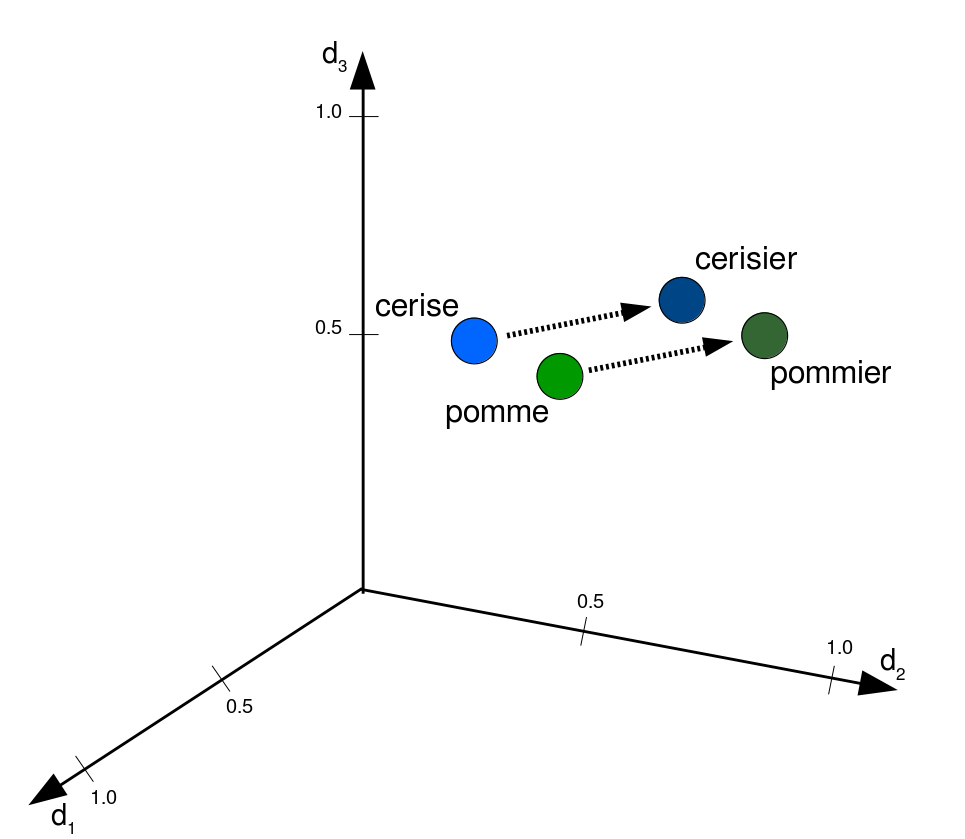
Word Embeddings: Semantik im Vektorraum (Ergebnis)
Word Embeddings: Training
Encoder-Modelle (BERT / Transformer)
BERT = Bidirectional Encoder Representations from Transformers
- Unterschiede zu statischen Word Embeddings
- Es wird nicht ein Lexikon repräsentiert, sondern ein Korpus
- Jedes Token hat je nach Kontext einen eigenen Vektor (it => animal!)
- Der Kontext wird in beide Richtungen berücksichtigt (bidirectional)
- Der Kontext wird je unterschiedlich gewichtet (“Attention”)
![]()
Neuere Entwicklungen
- Ansatz
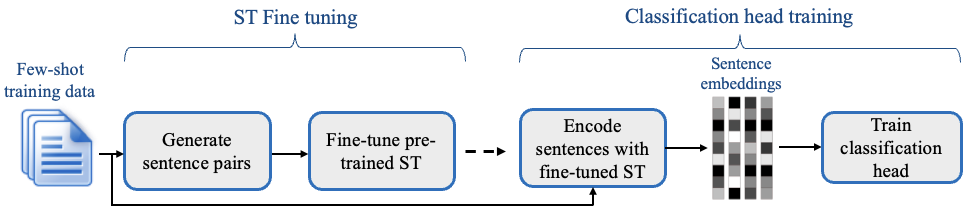
- Few-shot-learning: allgemeines Modell, lernt Task mit wenigen Beispielen
- Beispiel: SetFit (Few-Shot Learning for Sentence Transformers), Unso et al. (2022).
- Zero-shot-learning: allgemeines Modell, kann Task direkt ausführen
- Vor- und Nachteile
- Viel weniger Aufwand
- Technisch viel einfacher
- Performance nicht immer vorhersehbar
Multimodale Sprachmodelle
- Modelle, die mit Sprache, aber auch mit Bildern umgehen können (Decoder und/oder Encoder)
- Absoluter “game changer” für die Bildwissenschaften
- Erlaubt algorithmischen Zugang zum Bildinhalt (Objekte, Farben, Stile)

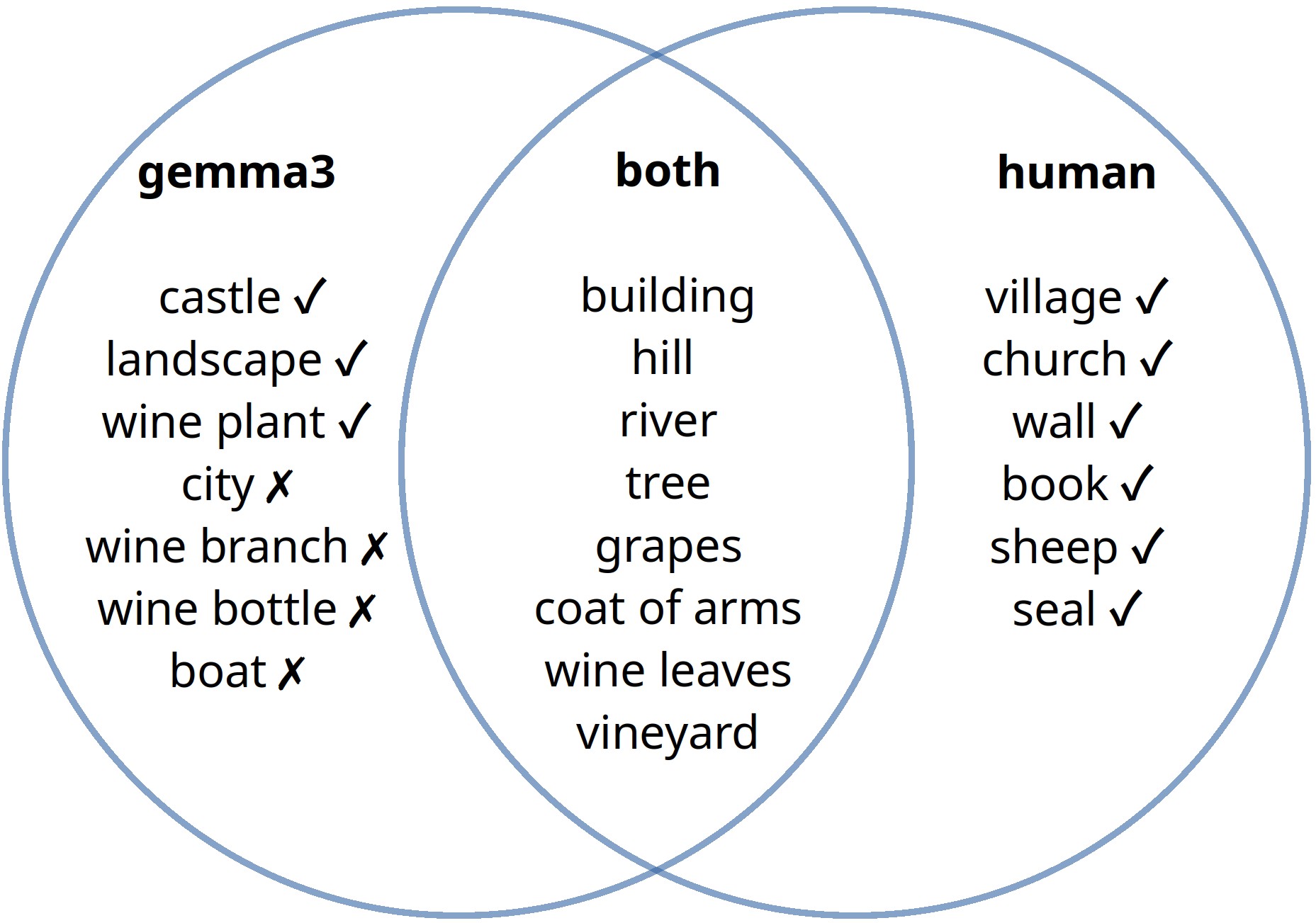
Offene, effiziente Modelle für lokalen Einsatz
- Sehr bequem bspw. über Ollama
- Bessere Reproduzierbarkeit
- Besserer Datenschutz
- Geringerer Ressourceneinsatz
- Keine Top-Performance
- Modelle für Text, Bild, Code etc.

Redewiedergabe-Projekt
- Automatische Erkennung von Redewiedergabe (direkt/indirekt/free indirect)
- Verschiedene Encoder-Modelle (BERT und FLAIR) mit Finetuning
- Erkennungsraten (F1): 0.84 (direkt), 0.76 (indirekt), 0.59 (free indirect)

MacBERTh
- MacBERTh: ein Transformer-basiertes Modell (BERT-style)
- Trainiert auf sehr viel historischem Englisch
- Verbesserte Performance auf historischen Daten für Standard-Tasks

ALBERTI
- Zwei Aufgaben: stanza type classification, metrical pattern prediction
- Mehrsprachige, für den Task trainierte BERT-Modelle
- Verbesserte Performance gegenüber generischen mehrsprachigen Modellen

‘Predict what happens next…’
- Grundidee: Ein LLM bekommt als Input
- Eine Zusammenfassung der Romanhandlung bis zum aktuellen Punkt
- Die 900 Wörter vor dem aktuellen Punkt
- Schritt 1
- Das 900-Wörter-Segment zusammenfassen
- Eine Zusammenfassung des nächsten Segments generieren
- Schritt 2
- Das LLM bekommt das tatsächliche nächste Segment
- Aufgabe: Zusammenfassung dieses Segments generieren
- Evaluation
- Wie ähnlich sind sich die beiden Zusammenfassungen?

Do LLMs understand poetry?
- Aufgabe: Prompt-basierte Interpretation von Gedichten
- Ergebnisse:
- sehr gut bei Kontext-abhängigen Fragen (!)
- nicht gut bei Fragen von Metrik und Reim (!)
- Nicht-englischer Kontext muss explizit aufgerufen werden

Sequence Labeling: Evalation

DraCor und MCP: Erfahrungen und Optimierung

Stilometrische Autorschafts-Attribution

Danke! Ich freue mich auf die Diskussion!
