Reflexion digitaler Methoden
Christof Schöch
Modul Reflexion digitaler Methoden
Master Digital Humanties
Universität Stuttgart
17 Jan 2025
Sitzung 1
Einführung und Überblick
Seminarplan
| # | Thema | Lektüren |
|---|---|---|
| 1 | Einführung und Orientierung / Organisatorisches | – |
| 2 | Grundbegriffe 1: Modell/Modellierung | Flanders / Jannidis 2015 |
| 3 | Grundbegriffe 2: Operationalisierung | Pichler / Reiter 2021 |
| 4 | Qualitative Methoden 1: Annotation | Nantke 2020 |
| 5 | Qualitative Methoden 2: Linked Open Data | Hogan 2020 |
| 6 | Anwendungsbeispiel: INTRO | Oberreither 2023 |
| 7 | Quantitative Methoden 1: Netzwerkanalyse | Trilcke 2013 |
| 8 | Quantitative Methoden 2: Stilometrie | Smith / Aldridge 2011 |
| 9 | Anwendungsbeispiel: Der Fall Elena Ferrante | Savoy 2020 |
| 10 | Quantitative Methoden 3: Large Language Models | Wolfram 2023 |
| 11 | [Konzept/Methode/Theorie nach Wunsch] | tbc. |
| 12 | Abschlussitzung: Rückschau und Fazit | – |
Kommentar
Das Seminar baut auf auf dem in das Fach einführenden Modul “Theoretische und informatische Grundlagen für die DH” (1. Semester) und dem anwendungsbezogenen Modul “Methoden der DH” (2. Semester) auf und fokussiert in erster Linie die “Lektüre, Vorstellung und Diskussion theoretischer Grundlagentexte der Digital Humanities” (Modulhandbuch).
Mit Blick auf die thematischen Schwerpunkte der Grundlagentexte wird das Seminar drei Bereiche fokussieren: Erstens theoretische Grundbegriffe der Digital Humanities (Modellierung, Operationalisierung); zweitens qualitative Methoden der Datenerschließung (Annotation, Linked Open Data); und drittens quantitative Methoden der Datenanalyse (Netzwerkanalyse, Stilometrische Autorschaftsattribution, Large Language Models). Diese Bereiche bzw. Texte werden sowohl in ihrer Eigenlogik als auch mit Blick auf das Selbstverständnis der Digital Humanities diskutiert.
Lernziele
Die Lernziele des Seminars sind folgende:
- Die Teilnehmenden werden vertiefte Kenntnisse der Stärken und Schwächen sowie der präferierten Einsatzgebiete mehrerer zentraler Konzepte und Methoden der Digital Humanities entwickeln;
- Sie werden in ausgewählten Fällen die grundsätzliche Leistungsfähigkeit der Methoden in ihrer konkreten Anwendung in der Forschung vergleichen lernen;
- Sie werden Lektürestrategien erwerben, um auch anspruchsvollere theoretische oder voraussetzungsreiche informatische Fachliteratur zu verstehen und kritisch zu hinterfragen.
Organisatorisches
- Es handelt sich um ein Pflichtmodul.
- Die Prüfungsform zum Erwerb von Leistungspunkte ist eine lehrveranstaltungsbegleitende Prüfung, die als studienbegleitende, benotete Leistungen umgesetzt wird.
- Konkret müssen Sie für vier von acht Lektüren in schriftlicher Form anspruchsvolle Lektürefragen (a) selbst formulieren und (b) auf der Grundlage der Lektüre sowie von Hintergrundrechechen selbst beantworten.
Lektüren und Materialien
NB.: Alle Lektüren werden Ihnen zu Beginn des Semesters über die Lernplattform zur Verfügung gestellt.
- Flanders, Julia, and Fotis Jannidis. “Data Modeling.” In A New Companion to Digital Humanities, 229–37. Wiley, 2015. https://doi.org/10.1002/9781118680605.ch16.
- Hogan, Aidan. “Chapter 2: Web of Data”. In: The Web of Data, 15–57. Springer, 2020.
- Nantke, Julia. “Annotationen : Werkzeug, Methode und Gegenstand der Digitalen Geisteswissenschaften.” In Wovon sprechen wir, wenn wir von Digitalisierung sprechen? : Gehalte und Revisionen zentraler Begriffe des Digitalen, 139–54. De Gruyter, 2020. http://publikationen.ub.uni-frankfurt.de/frontdoor/index/index/docId/55927.
- Oberreither, Bernhard. “A Linked Data Vocabulary for Intertextuality in Literary Studies, with some Considerations Regarding Digital Editions”. In: Digitale Edition in Österreich / Digital Scholarly Edition in Austria, hg. von Roman Bleier und Helmut W. Klug, 69–87. IDE, 2023.
- Pichler, Axel, and Nils Reiter. “Zur Operationalisierung Literaturwissenschaftlicher Begriffe in Der Algorithmischen Textanalyse. Eine Annäherung Über Norbert Altenhofers Hermeneutische Modellinterpretation von Kleists Das Erdbeben in Chili.” Journal of Literary Theory 15, no. 1–2 (2021): 1– 29. https://doi.org/10.1515/jlt-2021-2008.
- Smith, Peter W. H., and W. Aldridge. “Improving Authorship Attribution: Optimizing Burrows’ Delta Method.” Journal of Quantitative Linguistics 18, no. 1 (2011): 63–88. https://doi.org/10.1080/09296174.2011.533591.
- Savoy, Jacques. “Elena Ferrante: A Case Study in Authorship Attribution.” In Machine Learning Methods for Stylometry: Authorship Attribution and Author Profiling, edited by Jacques Savoy, 191–210. Springer,
- https://doi.org/10.1007/978-3-030-53360-1_8.
- Trilcke, Peer. “Social Network Analysis (SNA) als Methode einer textempirischen Literaturwissenschaft.” In Empirie in der Literaturwissenschaft, edited by Philip Ajouri, Katja Mellmann, and Christoph Rauen, 201–47. Mentis, 2013.
- Wolfram, Stephen. “What Is ChatGPT Doing … and Why Does It Work?” Stephen Wolfram Writings, Feb 2023. https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/.
Ergänzende Hintergrundlektüren
- Drucker, Johanna. The Digital Humanities Coursebook: An Introduction to Digital Methods for Research and Scholarship. Routledge/Taylor & Francis, 2021.
- Jannidis, Fotis, Hubertus Kohle, and Malte Rehbein, Hg. Digital Humanities: eine Einführung. Metzler, 2017.
- Schreibman, Susan, Ray Siemens, and John Unsworth, Hg. A Companion to Digital Humanities. Blackwell,
- https://companions.digitalhumanities.org/DH/.
- Schreibman, Susan, Ray Siemens, and John Unsworth, Hg. A New Companion to Digital Humanities. Blackwell, 2016.
Für weitere Lektürehinweise zu den großen Themen der Digital Humanities, siehe auch die Bibliographie auf Zotero.
Basis-Lektürefragen
- Was sind der Kontext / die disziplinäre oder andere Perspektive dieser Arbeit?
- Welche Konzepte stehen im Zentrum des Beitrags?
- Was sind die erklärten Ziele der Autor:innen?
- Welche(r) Datensatz(e) wurde(n) ggfs. verwendet?
- Welche Methoden wurden ggfs. angewandt?
- Welche Ergebnisse oder Erkenntnisse wurden erzielt?
- Welche Einschränkungen und nächsten Schritte werden genannt?
- Welche Stärken und Grenzen sehen Sie selbst?
- Welche neuen Erkenntnisse oder Ideen hat diese Arbeit bei Ihnen persönlich ausgelöst?
- Welche Aspekte der Arbeit waren für Sie schwer zu verstehen, und warum?
Grundbegriffe 1:
Modell/Modellierung
Grundbegriffe 2:
Operationalisierung
Qualitative Methoden 1:
Annotation
Qualitative Methoden 2:
Linked Open Data
Anwendungsbeispiel:
INTRO – Intertextual Relationships Ontology
Quantitative Methoden 1:
Netzwerkanalyse
Quantitative Methoden 2:
Stilometrische Autorschaftsattribution
Überblick
- Einführung in die Stilometrie
- Ähnlicher Stil, gleiche:r Autor:in?
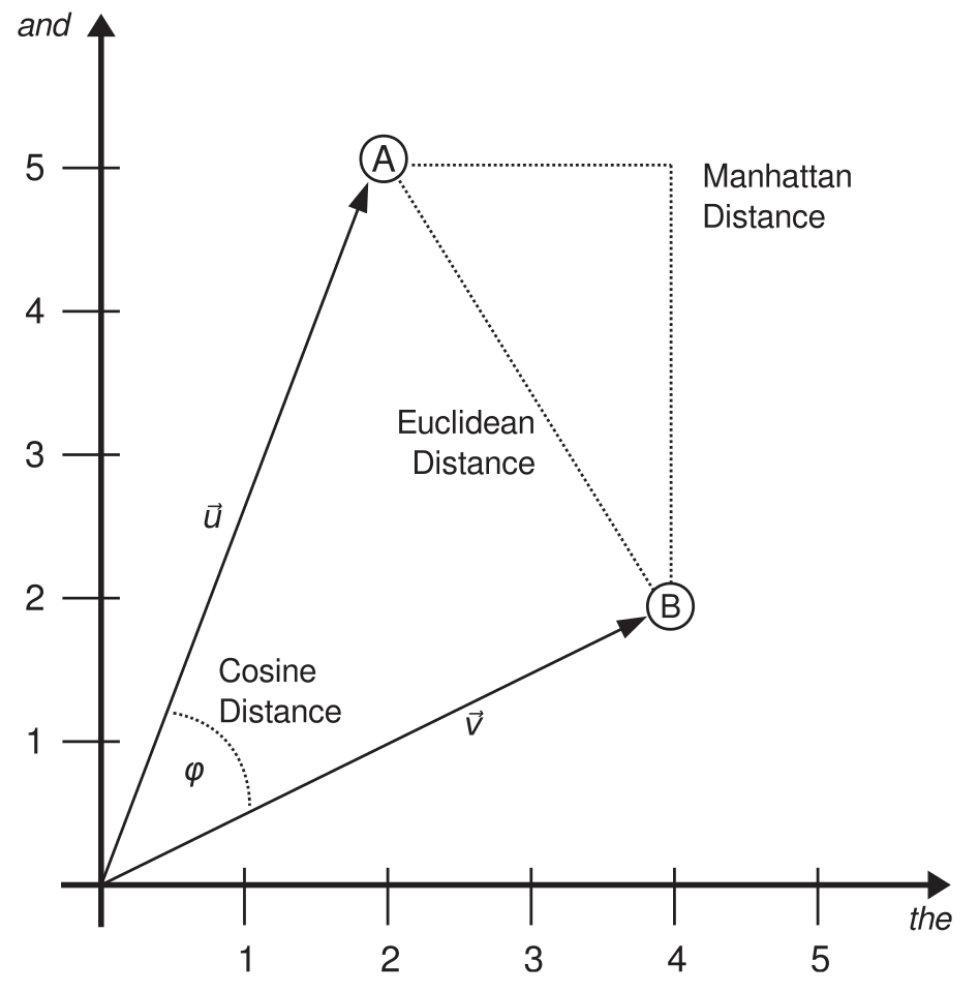
- Distanzmaße
- Relevante Parameter
- Smith and Aldridge 2011
- Zusammenfassung anhand der Basis-Lektürefragen
- Diskussion ausgewählter Lektürefragen der Teilnehmenden
- Die Suche nach den ‘besten Parametern’
- Interaktiver Showcase
- Einfluss von Sprache (und Korpus)
- Ausblick (nächste Sitzung)
- Anwendungsfall ‘Elena Ferrante’
Einführung in die Stilometrie
[…]
Smith and Aldridge 2011
[…]
Kurze Rekapitulation des bisher Gelernten
- Grundannahme der SAA: textuelle Ähnlichkeit => gleiche Autorschaft
- Grundfrage (Operationalisierung): Wie kann man textuelle Ähnlichkeit messen?
- John Burrows: Häufige Wörter + Vektor-Repräsentation + Distanzmaße
- Smith and Aldrige: Cosine als Distanzmaß + ~300 MFW als Merkmale
- Folgefrage: Wie generalisierbar sind diese Parameter?

Interaktiver Showcase ‘Multilingual Stilometry’ (Kontext)
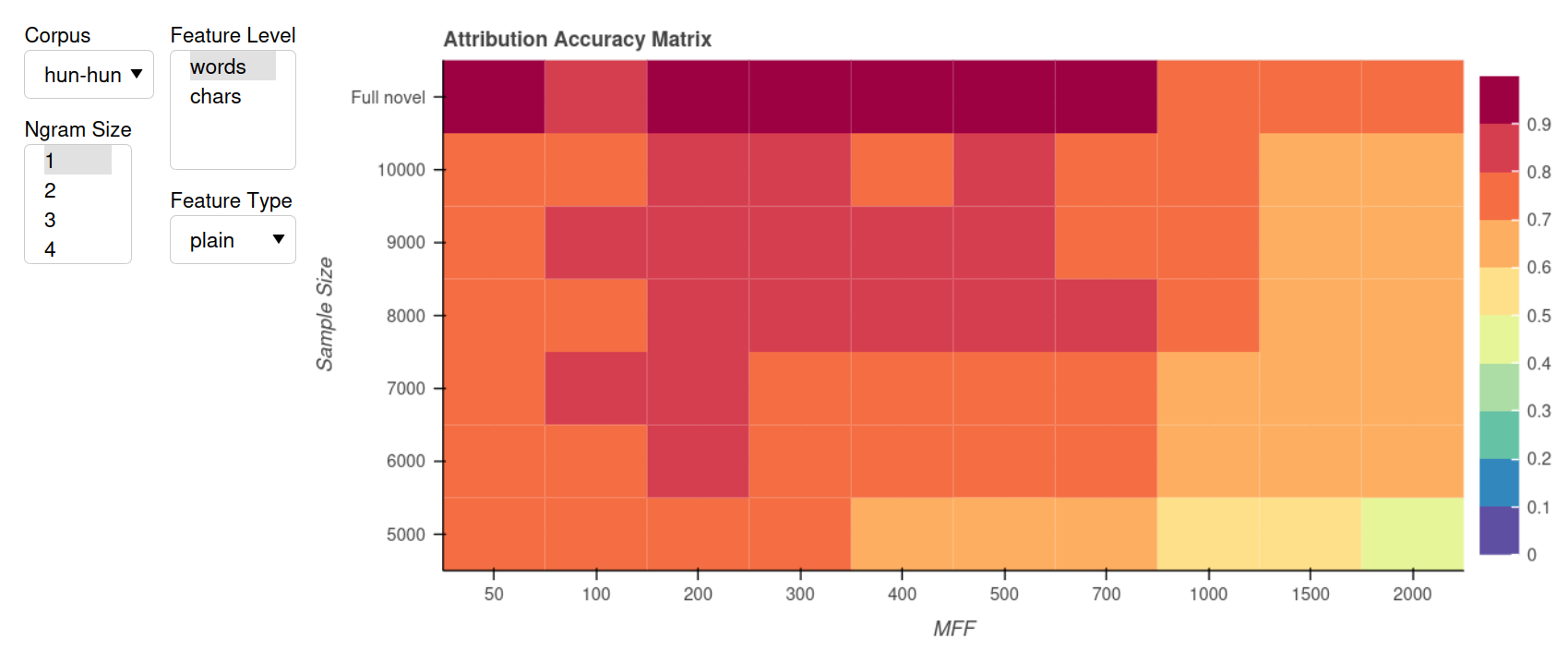
- Siehe: showcases.clsinfra.io/stylometry
- Stilometrische Benchmark-Analysen für Korpora in mehreren Sprachen
- Zeigt die Attributionsgüte in Abhängkeit verschiedener Parameter
- Hintergrundpaper: “Multilingual Stylometry” (CHR2024)
Interaktiver Showcase zur Stilometrie: Parameter

- Corpus: Originalsprache + Sprachfassung
- Feature level: Wörter oder Zeichen
- Feature Type (für Wörter): Wortformen, Lemmata, POS
- NGram Size: 1, 2, 3, 4, 5
Exploration des Showcases
- Wir öffnen (mit Laptop oder Handy) die Seite: showcases.clsinfra.io/stylometry
- Im Dialog können wir jetzt die Parameter nach Wunsch variieren
- Auch im Vergleich von zwei Parameter-Settings
- Achten Sie auf folgende Punkte
- Welches Korpus haben wir ausgewählt?
- Welche Effekte haben Änderungen an den Parametern?
- Welche weiteren Beobachtungen machen Sie?
Zusammenfassung: Einige Erkenntnisse
- Attributionsgüte:
- bei UKR insgesamt niedriger als bei den anderen Sprachen
- bei übersetzten Korpora niedriger als bei Originalen
- bei vollständigen Texten besser als bei kürzeren Segmenten
- Weitere Beobachtungen
- Je nach Korpus und Sprache variiert, welches die besten Merkmale sind
- Der “optimale Bereich” um 300 MFW (Smith and Aldridge) gilt vor allem bei Wort-Unigrammen
- Bei anderen Merkmalen kann das stark variieren
- Mehr Merkmale ist nicht unbedingt besser (warum?)
Ausblick: Nächste Sitzung
- Stilometrie-Anwendungsfall: Elena Ferrante
- Bitte Artikel von Jacques Savoy zu diesem Fall lesen ;-)
